
Microsoft Fabric is a knowledge analytics device that may show you how to streamline all of your information wants and workflows, from information integration to analytics and engineering.
In this information, I’ll clarify what Microsoft Fabric is in additional element, the way it works, and stroll you thru constructing a undertaking with it. If you have already got an understanding of the platform, you’ll be able to skip to the Microsoft Fabric undertaking.
Here’s what you may study on this information:
Prerequisites
To observe alongside, you’ll need to have a Power BI license. You can get one at no cost to follow with utilizing the Microsoft 365 Developer Program.
It can be even be useful when you have information of Microsoft Power BI and Python.
What is Microsoft Fabric?
Microsoft Fabric is an all-in-one analytics software-as-a-service (SaaS) platform for managing all of your information analytics wants and workflows. Microsoft constructed this end-to-end platform to deal with data-related information, out of your information storage and migration to your real-time information analytics, information science tasks, and information engineering workflow.
But how does it work?
This device brings collectively varied new and preexisting information instruments and applied sciences—Power BI, OneLake, Azure Data Factory, Data Activator, Power Query, Apache Spark, Synapse Data Warehouse, Synapse Data Engineering, Synapse Data Science, Synapse Real-Time Analytics, Azure Machine Learning, and varied connectors.
Why You Should Learn About Microsoft Fabric
The finest a part of Microsoft Fabric is its simplicity when it comes to performance. Using varied applied sciences collectively, you are able to do all the pieces multi function place and focus extra on what you are able to do with it and fewer on licensing, supporting programs, dependencies, and methods to combine with all these completely different platforms.
Another good thing about the platform is the way it handles your information. This offers and permits you to preserve a single dependable supply of data. With Microsoft Fabric’s OneLake, you’ll be able to have a single, unified information storage.
Microsoft Fabric additionally has Azure’s OpenAI service built-in into its layer. This manner, you need to use AI (Co-pilot) that will help you uncover insights rapidly.
Lastly, since it’s an all-in-one platform, there’s a cost-saving edge since there isn’t a must subscribe to a number of distributors.
Microsoft Fabric Architecture
Think of Microsoft Fabric as your information property.
Just like every bit of actual property, Microsoft Fabric has varied elements in its structure.
Let’s begin by wanting on the terminology you may encounter and want to grasp when utilizing Microsoft Fabric’s structure:
Experiences and Workloads:
These seek advice from the assorted capabilities of the platform. Every expertise on the platform is tailor-made with a particular person in thoughts.
Below are some examples of the assorted experiences/workloads accessible. You’ll discover that every of them are constructed for a particular goal, process, and person.
- Data manufacturing facility: This utility provides customers over 150 connectors to Lakehouses, warehouses, cloud, and on-premise information sources and orchestrates information pipelines for information transformation. A Lakehouse right here refers to an information platform for storing structured and unstructured information. You also can copy your on-prem information to the cloud and cargo it into OneLake by the Data Factory.
- Synapse information engineering is a part of the info engineering expertise on the platform. It has some cool options like Lakehouses, constructed information pipelines, and a Spark engine.
- Synapse information warehouse offers you with a unified and serverless SQL engine. Like your “conventional” information warehouse, you’ve got the complete capabilities of your transactional T-SQL options.
- Synapse real-time analytics permits you to stream information from Internet of Things (IoT) units, telemetry, and logs. You also can use the workload right here to investigate semi-structured information utilizing its Kusto Query Language (KQL) capabilities, similar to Azure Data Explorer.
- Synapse information science permits you to construct, collaborate, practice, and deploy absolutely scalable end-to-end Machine studying (ML) and AI fashions. You also can perform your ML experiments in your notebooks and log your fashions utilizing the Fabric Auto Logging function. A must-mention device on this expertise is the Data Wrangler, a Fabric graphical person interface for information transformation. With this device, you’ll be able to clear your information by simplifying by clicking buttons whereas the device routinely generates the Python code for you. It is much like Power Query.
- Business Intelligence with Power BI helps you rapidly flip your online business information into insightful analytic experiences and dashboards.
- Data Activator permits you to handle your information observability and monitor workloads in a non-code/low-code manner. This tells you when particular information factors hit a threshold or match a sample. You also can automate specific actions and kickoff Power Automates flows when particular circumstances happen.
- Copilot in Fabric offers you with an Azure OpenAI Service. This means you’ll be able to construct experiences, describe the way you need to ingest your information, summarize, discover, and rework your information utilizing the pure language functionality of Azure OpenAI.
Workspaces
Workspaces are much like Power BI’s workspace. Here, you’ll be able to share and collaborate with others and create experiences, Warehouses, Lakehouses, dashboards, and notebooks.
Capacity Unit (CU)
A CU is the power of your useful resource to carry out or produce an output.
Now we’ll take a look at the assorted elements of Microsoft Fabric’s structure.
OneLake
OneLake is the central information repository for Microsoft Fabric that shops the info in Delta Lake format. Think of it as OneDrive to your information. This repository permits you to discover and discover information property in your group.
One thrilling factor is Shortcuts, which lets you share or level to information in different areas in OneLake with out shifting or duplicating the info. This removes any case of information redundancy.
Lakehouses vs Warehouses
While each “homes” maintain information, some variations exist between Lakehouses and Warehouses in Microsoft Fabric.
For starters, a Lakehouse can retailer any information sort, whether or not structured or unstructured. It is, nevertheless, saved within the Delta format by default. The Delta format is a storage layer that gives ACID (Atomicity, Consistency, Isolation, Durability) transactions. A Warehouse, alternatively, is extra fitted to structured information.
Lakehouses additionally assist Notebooks. So you’ll be able to work with varied languages from PySpark to SQL and R. Warehouses, alternatively, solely use SQL.
Keep in thoughts, although, that Fabric offers you with two forms of Warehouses: SQL Endpoint and Synapse Data Warehouse.
- SQL Endpoint is auto-generated when a Lakehouse is created. This imply you’ll be able to have a SQL-based expertise and might question Lakehouse information utilizing T-SQL language.
- Synapse Data Warehouse is extra of your conventional SQL engine. So you need to use it to create and question information out of OneLake.
How to Get Started With Microsoft Fabric – An End-to-End Project Example
To get a glimpse of how the Fabric platform works, we are going to construct slightly undertaking.
We’ll create a Lakehouse to retailer a mall dataset from Kaggle utilizing the Kaggle API. We may also rework our information utilizing Data Wrangler. Then, we are going to carry out buyer segmentation on our information based mostly on the shopper’s annual revenue and spending rating utilizing the OkayMeans clustering algorithm. This will enable us to group the shoppers into varied classes like low revenue earners that do not spend, common revenue incomes clients, and excessive revenue clients who don’t spend a lot.
Let’s get began.
How to Enable Fabric
The very first thing we have to do is to log into Microsoft Power BI. Here, we are going to activate Microsoft Fabric’s capabilities for our workspace.
To do that, observe these steps:
First, navigate to the capability settings within the admin portal. The admin portal is the place directors management and handle the assorted Power BI options.
Then underneath the Tenant setting tab, search for Microsoft cloth tab.
Under that tab, allow the Users can create cloth objects toggle to on. Once you have completed that, choose Apply.
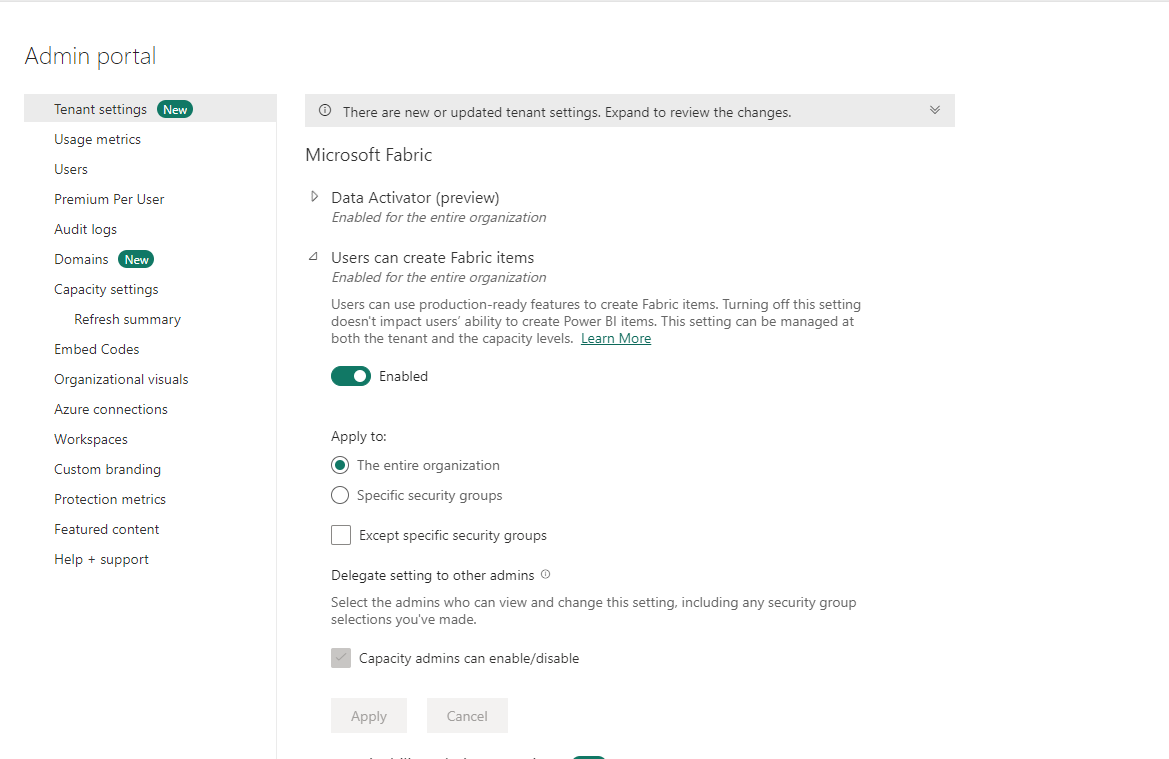
Now your surroundings can be arrange and the assorted companies ought to seem on the backside left of your display screen.

How to Create a Workspace in Microsoft Fabric
We’ll use a mall buyer segmentation dataset from Kaggle for this demo. This information, as talked about in Kaggle, was created for the aim of studying buyer segmentation ideas.
Let’s discuss slightly bit concerning the dataset. Imagine you’ve got a grocery store mall and every buyer has a membership card. You even have a knowledge catalog of every buyer with primary data like their buyer ID, age, gender, annual revenue and spending rating.
Now we need to section these buyer into varied teams so we will enhance buyer loyalty, perceive the shoppers higher, and extra successfully goal our advertising technique.
To obtain this, we are going to use the spending rating assigned to every buyer to outline their buying energy.
To get began, you may must create a brand new workspace. You can try this by following these steps:
- Head to your Microsoft Fabric residence web page.
- Select workspaces and click on on New Workspace.
- Give your workspace a reputation – I’m calling mine FabricMall.
- Click on Advanced to view the dropdown choices and choose Trial in case you are making use of your Fabric trial.
- Click Apply.
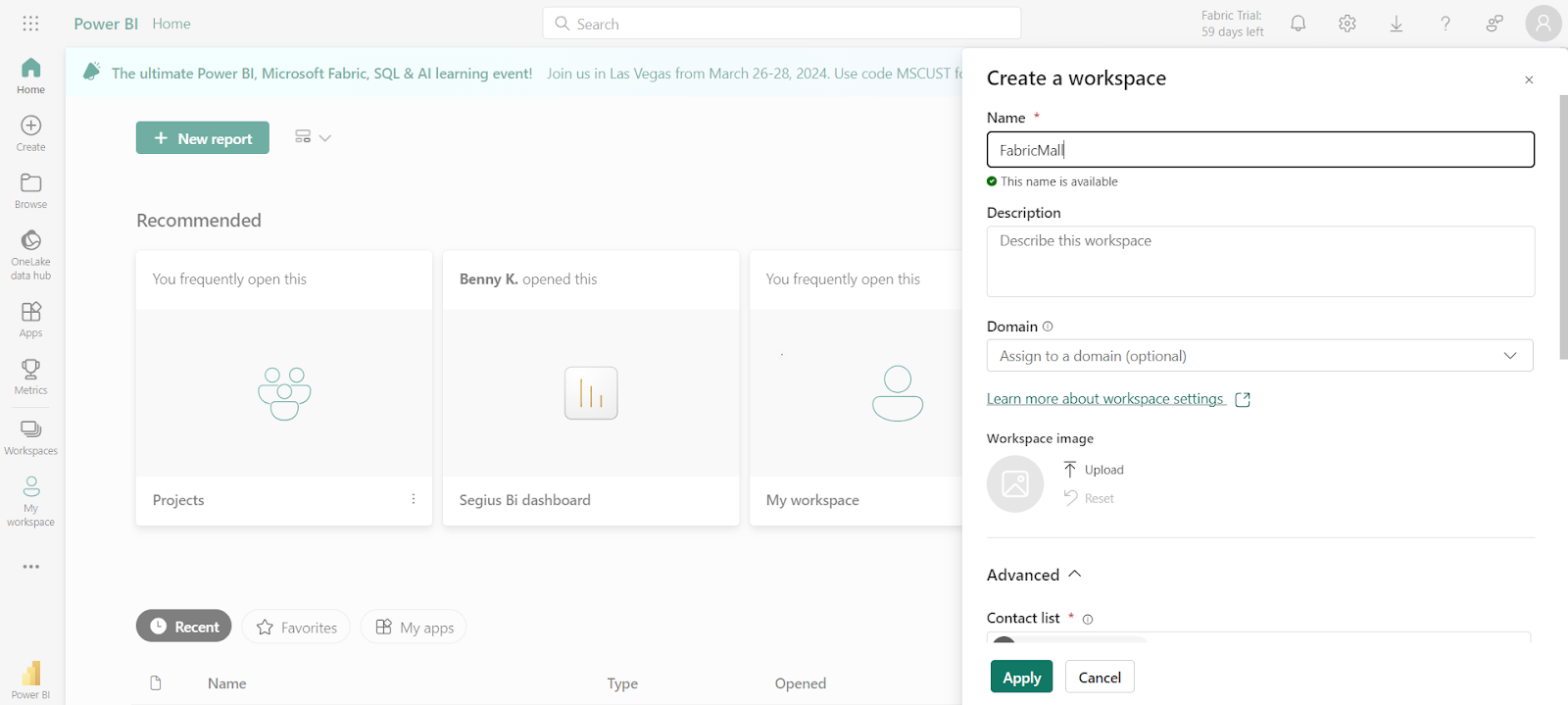
The subsequent factor you need to do is to create a Lakehouse to your information.
How to Create a Lakehouse in Microsoft Fabric
To create a Lakehouse, first click on on New inside your workspace. This will show an inventory of assorted duties you are able to do inside your workspace.
Then choose More choices and choose Lakehouse.
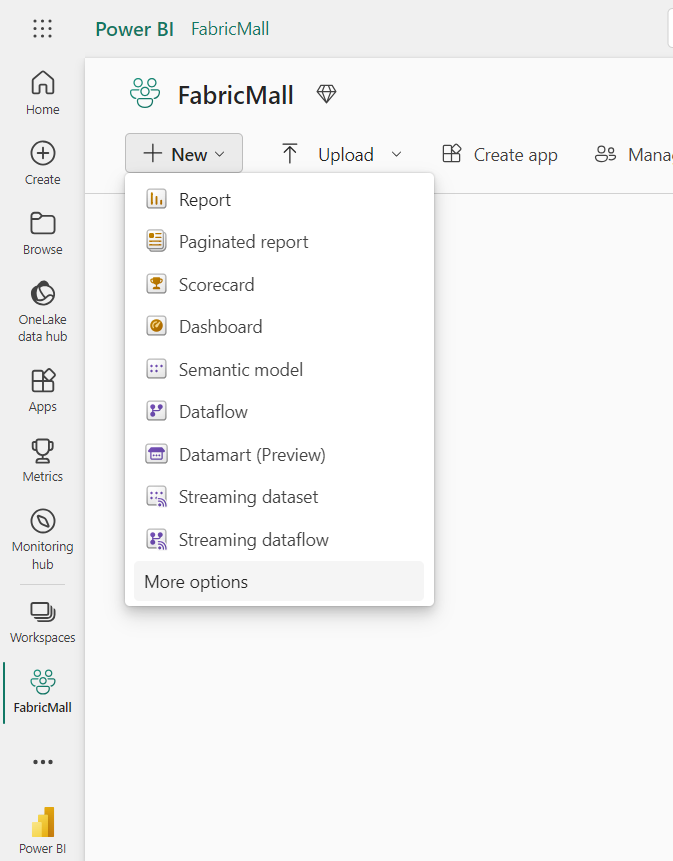
Then give it a reputation, like FabricMallLake, and click on on Open pocket book.
Click on New pocket book and Open. You can rename your pocket book on the high left nook of your pocket book. The pocket book is much like the Jupyter pocket book expertise.
How to Use Kaggle API Data in Microsoft Fabric
Notebooks enable us to write down, visualize, and execute code. Within the Notebook, we are going to use Python to carry out a buyer segmentation on our information in Microsoft Fabric.
First, import Kaggle utilizing the command beneath:
!pip set up KaggleNext, you may must import your working system and hook up with the Kaggle API.
import os
os.chdir('/lakehouse/default/Files')
os.environ['KAGGLE_USERNAME'] = 'bennyifeanyi'
os.environ['KAGGLE_KEY'] = '050019167fbe0027359cdb4b5eea50fe'
from kaggle.api.kaggle_api_extended import KaggleApi
api = KaggleApi()
api.authenticate()
api.dataset_download_file('vjchoudhary7/customer-segmentation-tutorial-in-python', 'Mall_Customers.csv')In the code above, os.chdir('/lakehouse/default/Files') represents our File API path. Also bear in mind to interchange the username and API Key with your individual.
Now import Pandas. This will can help you learn your file.
import pandas as pd
df = pd.read_csv("/lakehouse/default/" + "Files/Mall_Customers.csv")
df.head()But earlier than we begin segmenting our clients, let’s rework our information by exploring the info wrangler.
How to Use the Data Wrangler in Microsoft Fabric
One of essentially the most thrilling issues about this pocket book is that you could carry out information cleansing duties with out writing code utilizing the Data Wrangler.
To try this, click on on Data on the ribbon and choose Transform DataBody in Data Wrangler.
We will carry out the next transformations:
- We will convert the gender column to lowercase.
- We may also rename the columns with particular characters just like the greenback signal, brackets, and a splash. This is as a result of I seen Fabric finds it laborious to deal with these characters for the time being.
To do these transformations, observe these steps:
Under the Operation tab, choose Convert textual content to lowercase.
Pick the column – Gender on this instance – and choose Apply. This will convert your Gender column to lowercase and routinely generate the codes.
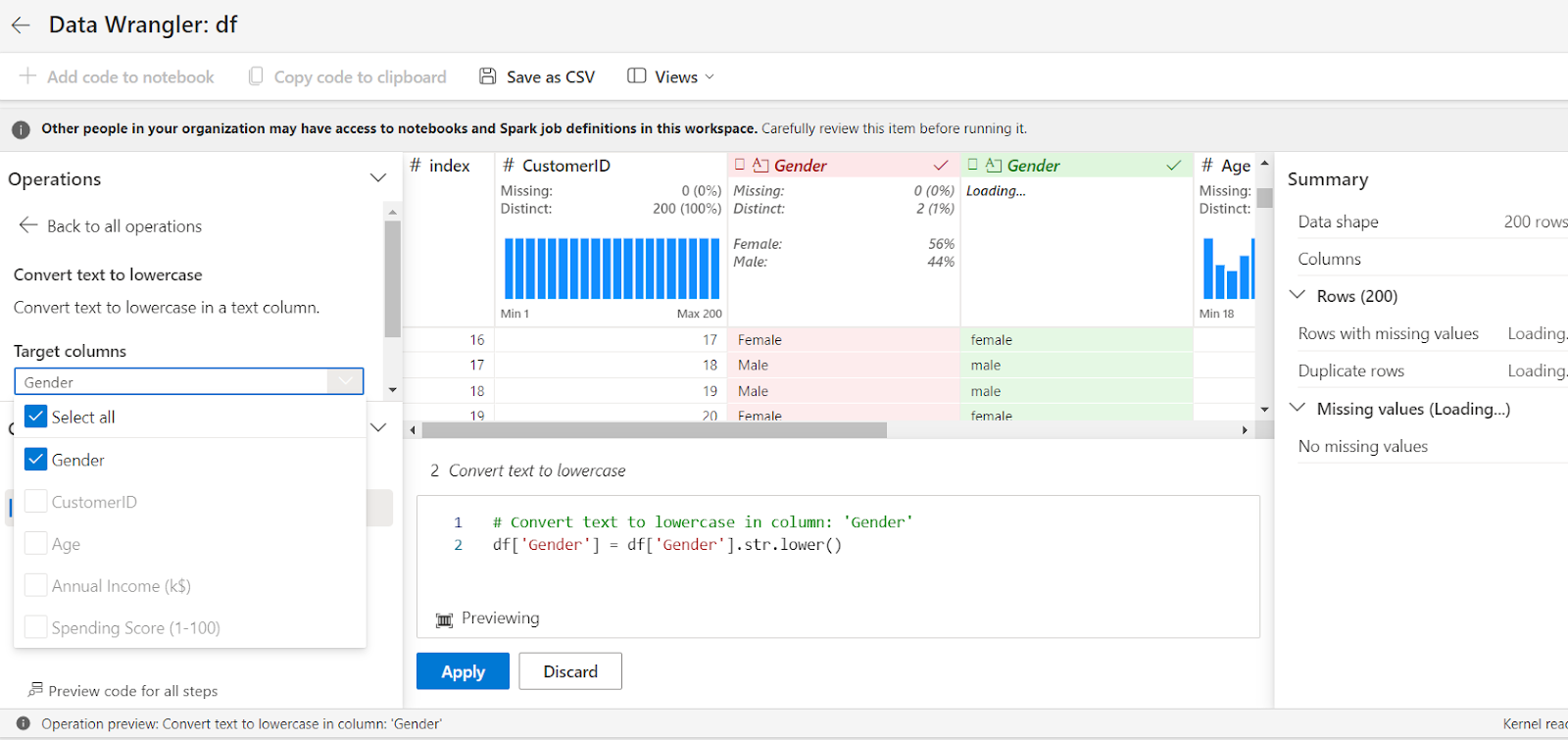
Similarly, underneath the schema tab, choose rename columns.
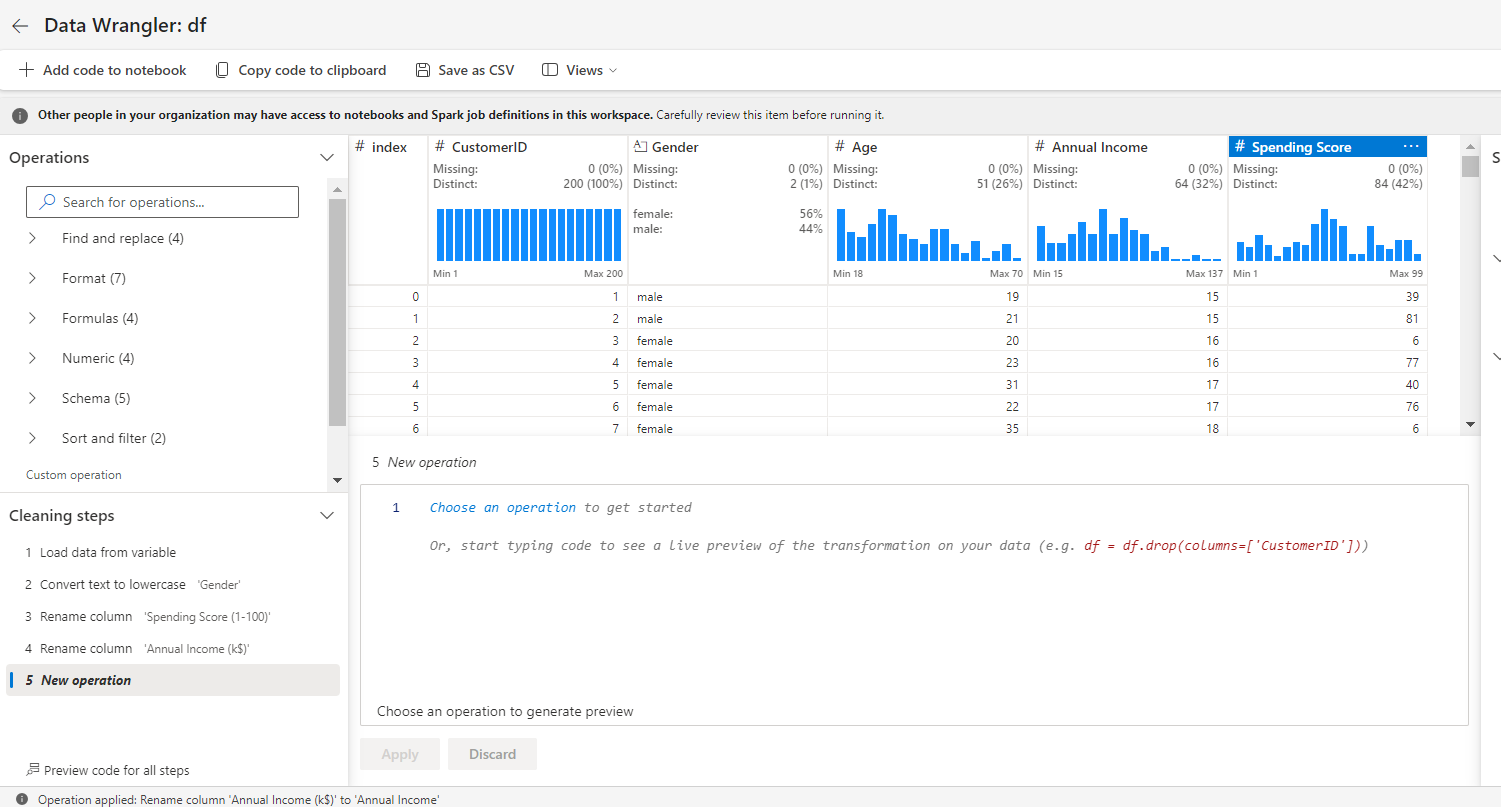
Rename Annual Income (ok$) to AnnualIncome, and Spending Score (1-100) to SpendingScore.
Once you’re completed with the transformation, click on Add code to pocket book.
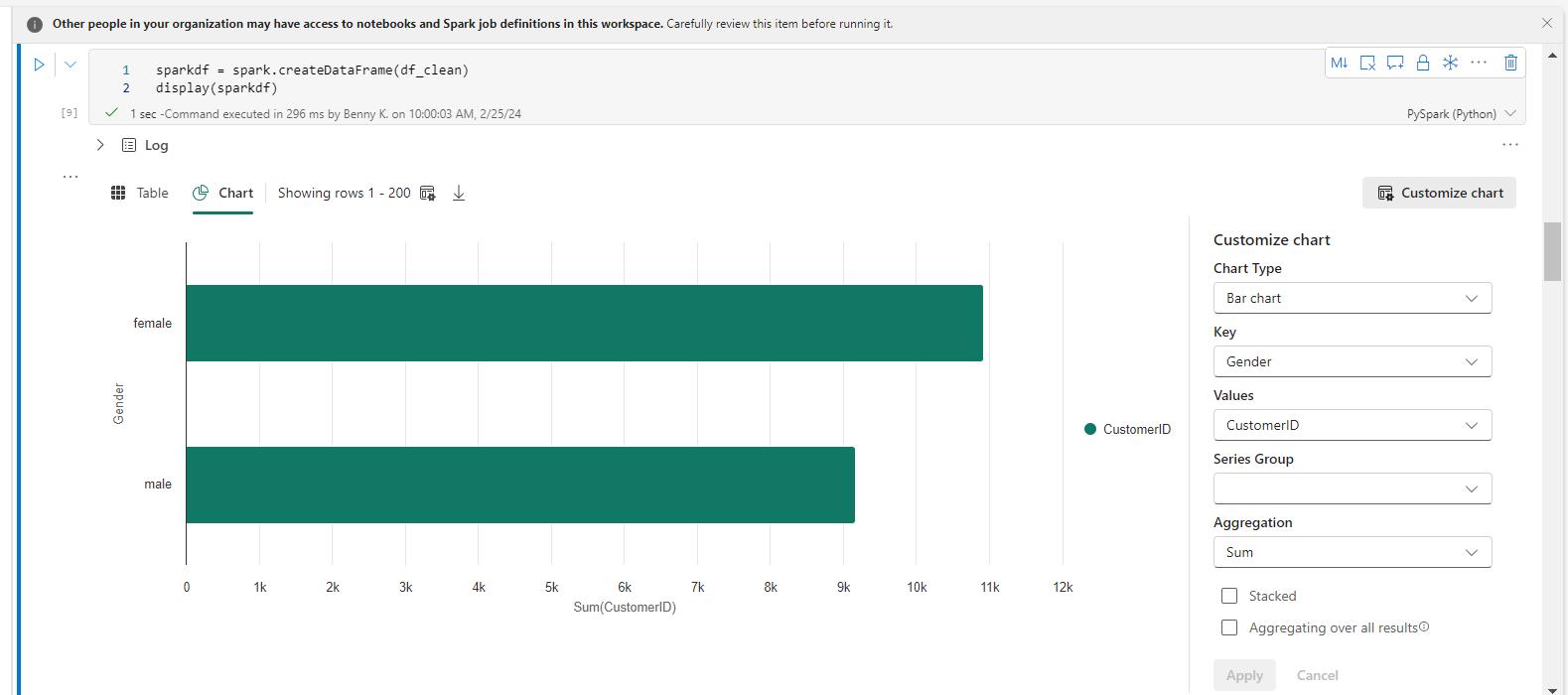
Back within the pocket book, we will visualize our information utilizing the code beneath:
sparkdf = spark.createDataBody(df_clean)
show(sparkdf)Within the chart component created, choose Customize chart. Pick the columns you need and choose Apply.
Once that is completed, we will save the info within the Lakehouse utilizing this code beneath:
sparkdf.write.format("delta").mode("overwrite").saveAsTable("malldatadf")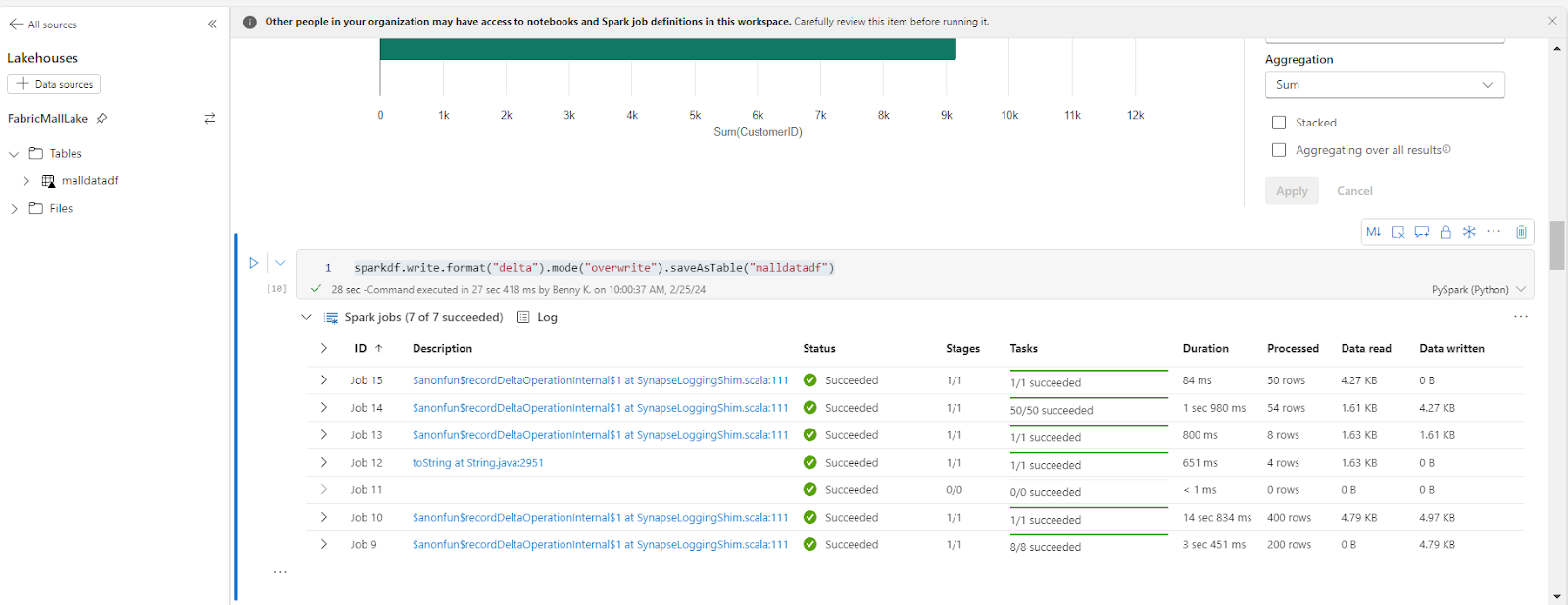
How to Perform Customer Segmentation in Microsoft Fabric
For our buyer segmentation, we are going to use the OkayMeans clustering algorithm to section the shoppers based mostly on their annual revenue and spending rating.
Okay-means clustering is an unsupervised machine studying algorithm. It teams related information factors in your information based mostly on underlying observations, similarities, and enter vectors.
We will do that by importing our libraries, making use of our Okay-means by coaching the Okay-Means clustering mannequin, and visualizing the clusters of consumers based mostly on their annual revenue and spending rating.
We may also embody and present the centroids of every cluster, offering insights into the distribution of consumers within the dataset.
The centroids right here refers back to the middle factors of the clusters discovered by our algorithm. This is calculated as the typical of all the info factors in that cluster. When we visualize the clusters, the centroid can be represented with a definite image or colour.
Run this code to realize this:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.cluster import OkayMeans
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
X = df_clean[['AnnualIncome', 'SpendingScore']]
# Feature normalization
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
kmeans = OkayMeans(n_clusters=5, init="k-means++", random_state=42)
kmeans.match(X_scaled)
plt.determine(figsize=(10, 8))
for cluster_label in vary(5): # Loop by every cluster label
cluster_points = X[kmeans.labels_ == cluster_label]
centroid = cluster_points.imply(axis=0) # Calculate the centroid because the imply place of the info factors
plt.scatter(cluster_points['AnnualIncome'], cluster_points['SpendingScore'],
s=50, label=f'Cluster {cluster_label + 1}') # Plot factors for the present cluster
plt.scatter(centroid[0], centroid[1], s=300, c="black", marker="*", label=f'Centroid {cluster_label + 1}') # Plot the centroid
plt.title('Clusters of Customers')
plt.xlabel('Annual Income (ok$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.present()Here’s the output:
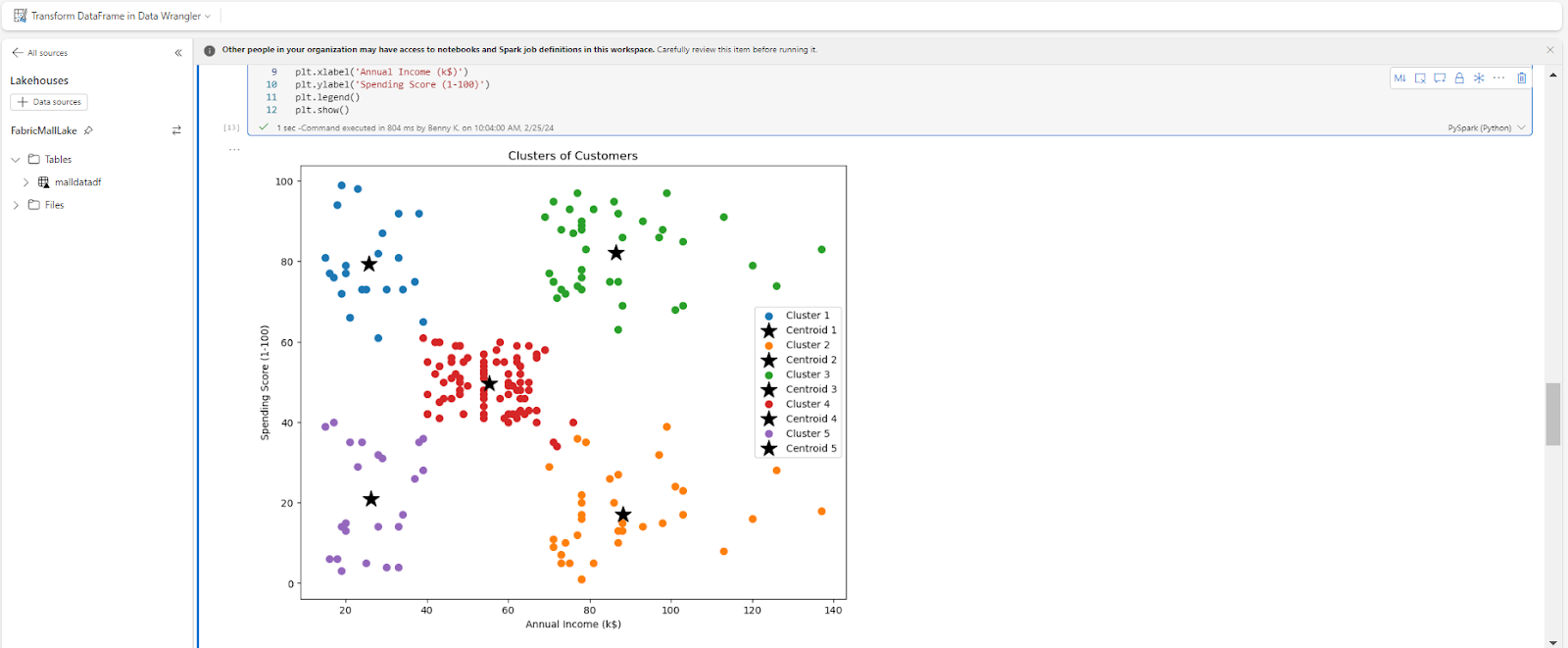
The results of our evaluation reveals that our clients may be grouped into 5 clusters:
- Cluster 1 (Purple) are low revenue earners with a low spending rating.
- Cluster 2 (Blue) are low revenue earners with a excessive spending rating.
- Cluster 3 (Red) are common revenue incomes clients with important spending scores.
- Cluster 4 (Orange) are excessive revenue clients who don’t spend a lot on the mall. They’re in all probability not glad with the companies rendered.
- Cluster 5 (Green) are excessive revenue clients with a excessive spending rating.
We also can save our prediction as a brand new dataset utilizing this code:
# Create a brand new DataBody to retailer the clustering outcomes
cluster_df = pd.DataBody(information=X, columns=['AnnualIncome', 'SpendingScore'])
cluster_df['Cluster'] = cluster_label
sparkclusterdf = spark.createDataBody(cluster_df)
sparkclusterdf.write.format("delta").mode("overwrite").saveAsTable("clusterdatadf")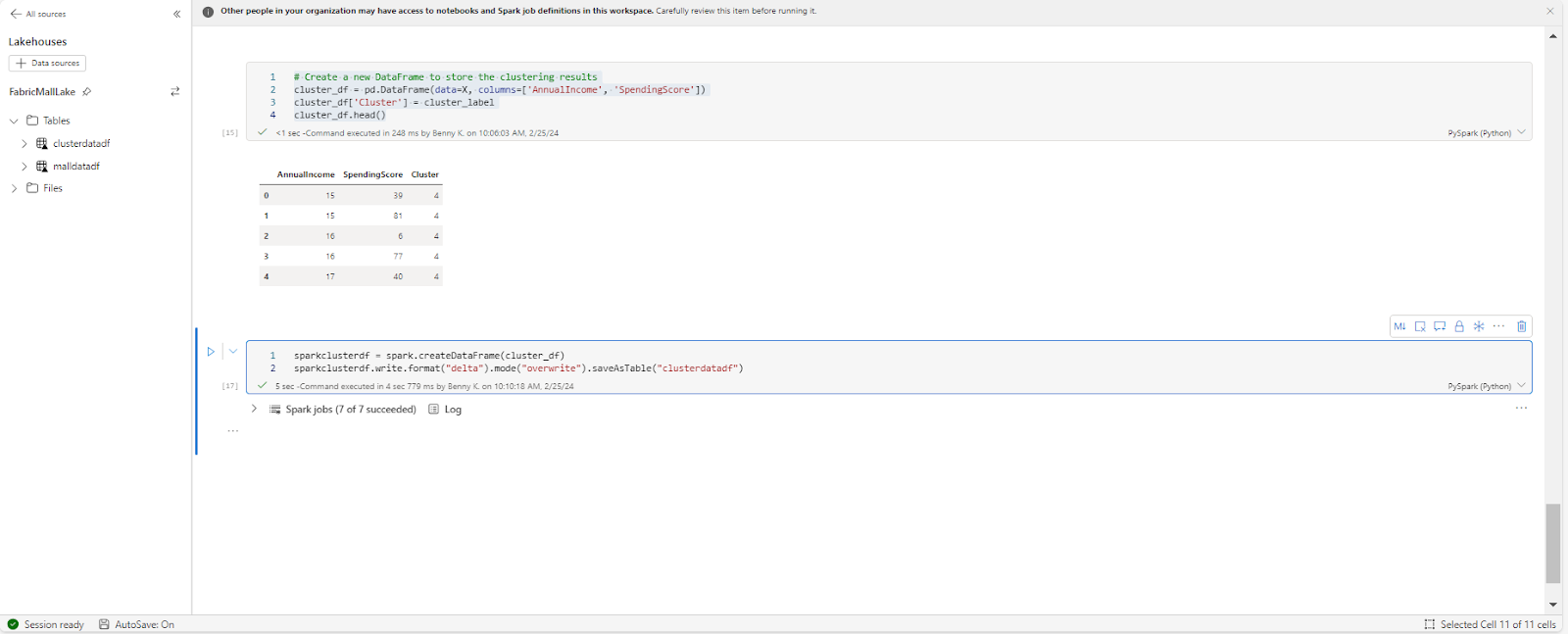
Want to check out the pocket book? You can obtain it from my GitHub.
How to Visualize Lakehouse Data in Power BI
Now we will determine to visualise our information on a dashboard inside Fabric.
Head again to the FabricMall workspace and choose the semantic mannequin sort of the FabricMallLake Lakehouse.
Then choose Manage default semantic mannequin.
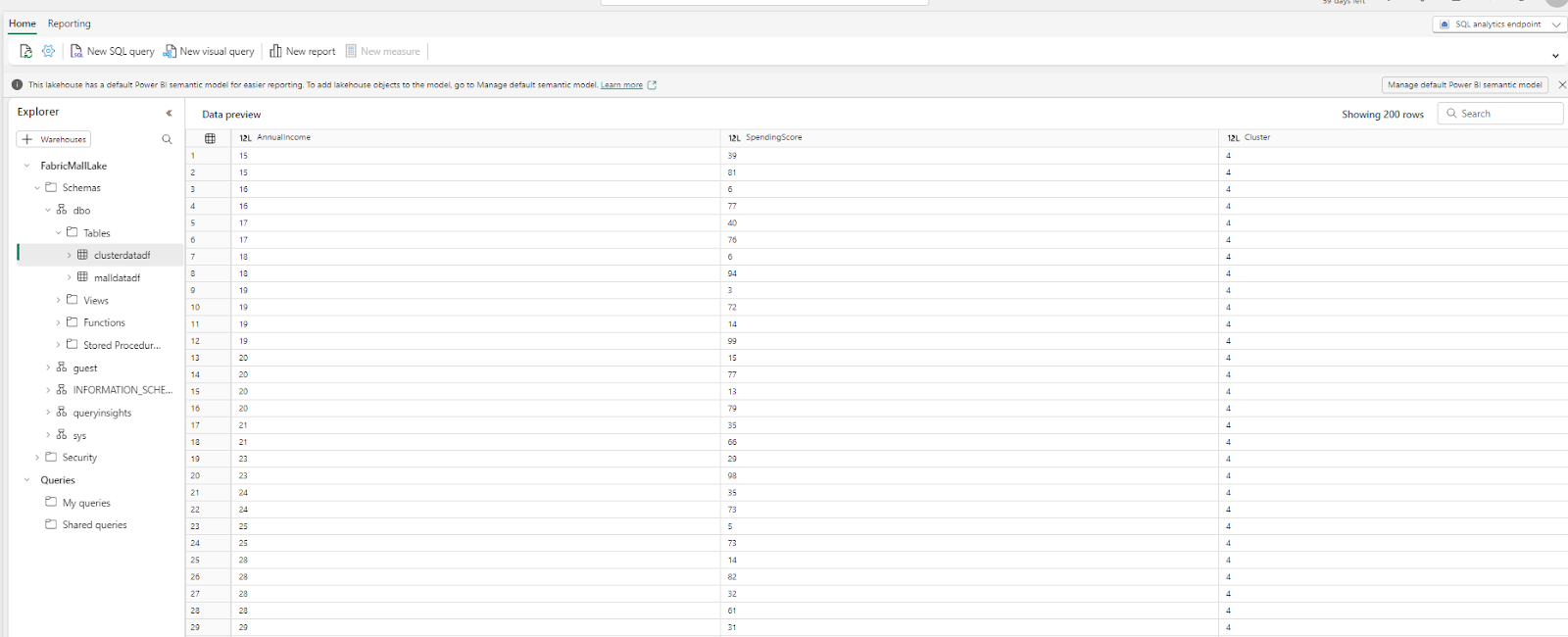
Pick your dataset, click on Confirm, after which choose New Report.
Let’s visualize the typical age in our information. To do that, click on on the cardboard visible and drag the age into this card. This will routinely create a visible displaying the typical age in your dataset.
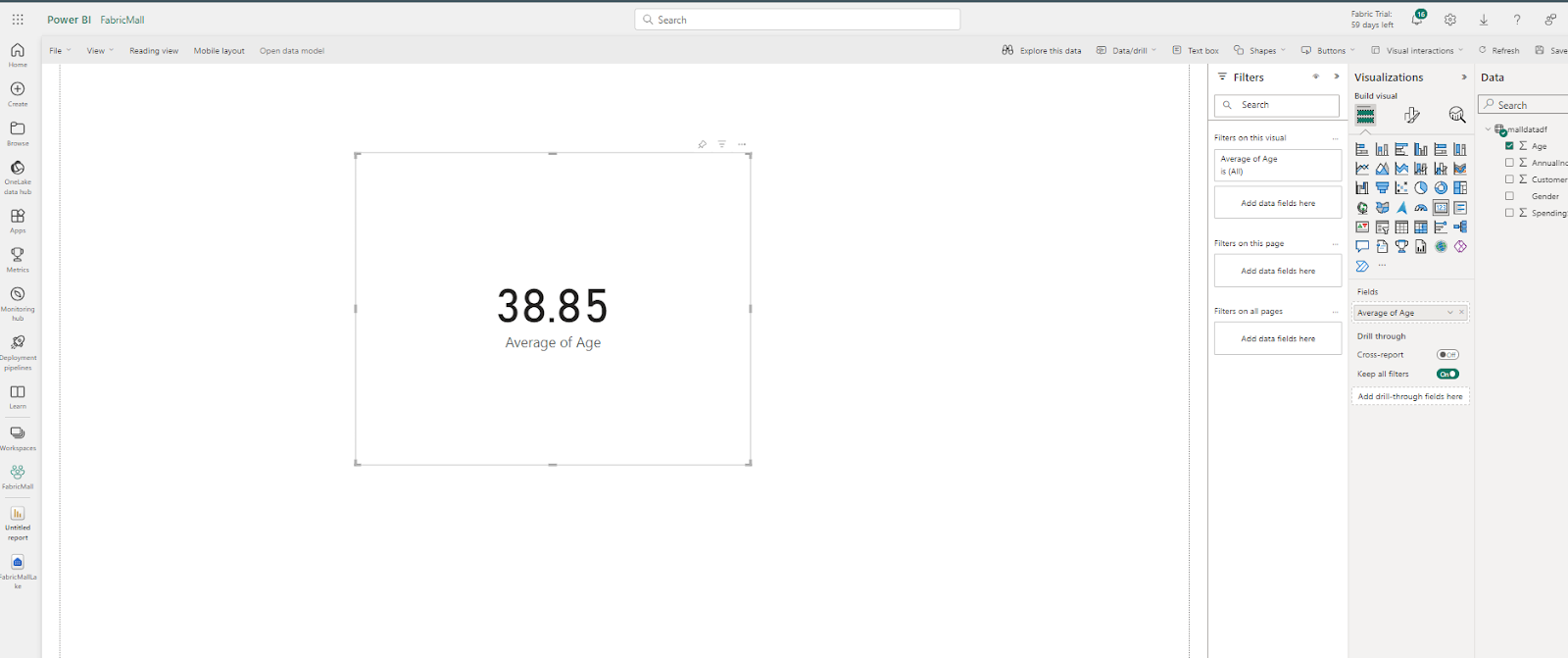
Just like in Power BI Desktop, you’ll be able to create your measure, construct your report, and publish your dashboard. You can be taught extra about methods to create visuals in Power BI utilizing this free freeCodeCamp YouTube information evaluation video.
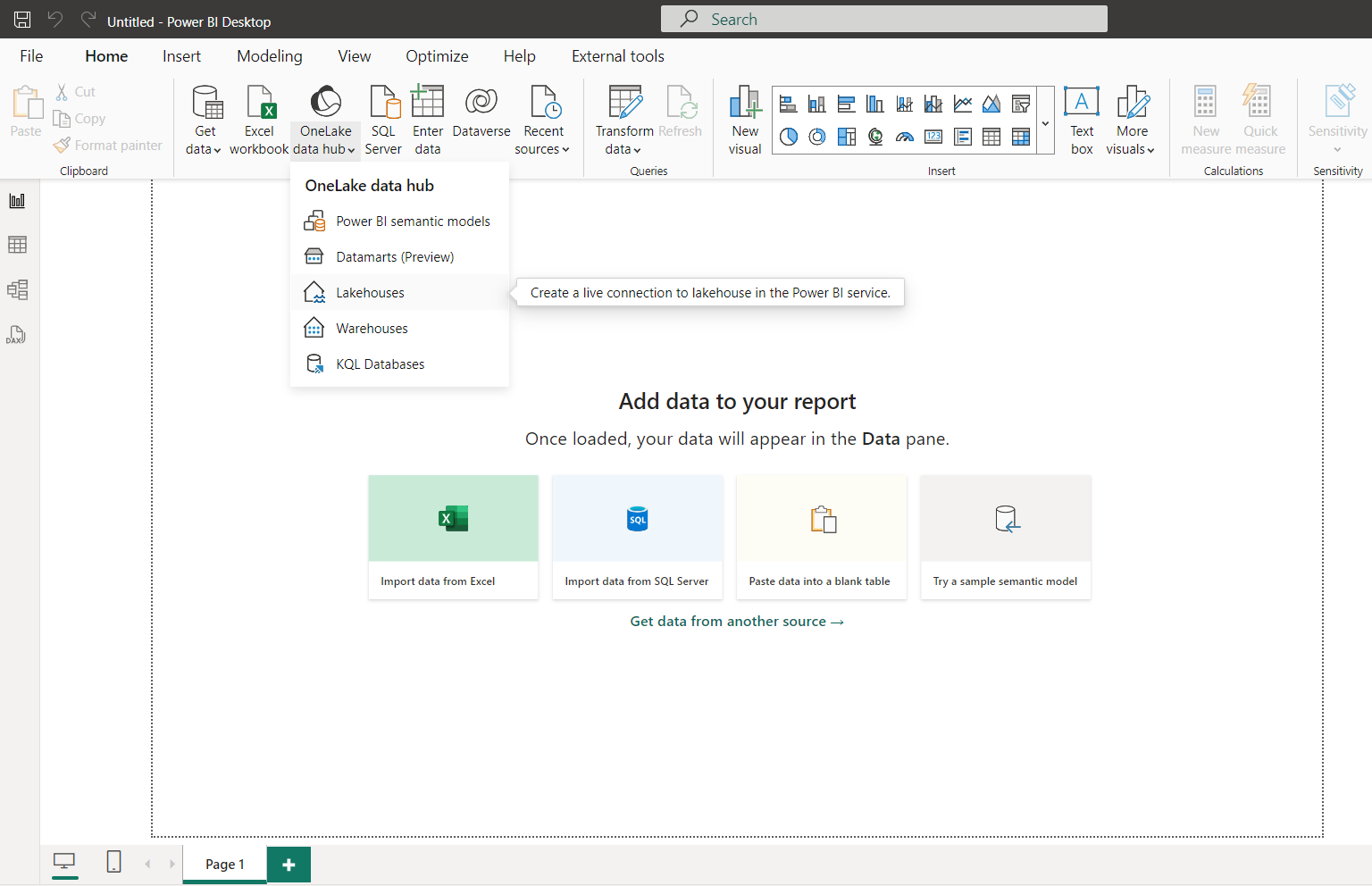
Alternatively, you’ll be able to open Power BI Desktop, and hook up with your Lakehouses from Onelake information hub.
Where Can I Learn More about Microsoft Fabric?
Though Microsoft Fabric is a reasonably new information platform, I hope you’ll be able to inform that this device will show you how to ease the way in which you and your group devour, analyze, and get perception out of your information.
To be taught extra you can begin with the cloth official documentation or any useful YouTube tutorial like Francis’s Fabric course. I might additionally advise you to start out with freeCodeCamp’s Fabric publication tags if you need a compilation of assets.
Lastly, should you’re new to information evaluation, begin your journey at present with freeCodeCamp’s Data Analyst Bootcamp for Beginners on YouTube. It covers all the pieces from SQL, Tableau, Power BI, and Python to Excel, Pandas, and real-life tasks constructing.
If you loved studying this text and/or have any questions and need to join, yow will discover me on LinkedIn, Twitter and do take a look at my articles on freeCodeCamp.