 to Create")
Hey there! So, you understand that buzz about Tesla’s autopilot being all futuristic and driverless? Ever considered the way it truly does its magic? Well, let me let you know – it is all about picture segmentation and object detection.
What is Image Segmentation?
Image segmentation, mainly chopping up a picture into completely different elements, helps the system acknowledge stuff. It identifies the place people, different automobiles, and obstacles are on the street. That’s the tech ensuring these self-driving automobiles can cruise round safely. Cool, proper? 🚗
During the previous decade, Computer Vision has made huge strides, particularly in crafting super-sophisticated segmentation and object detection strategies.
These breakthroughs have discovered various makes use of, like recognizing tumors and ailments in medical photographs, maintaining a tally of crops in farming, and even guiding robots in navigation. The tech’s actually branching out and making a major affect throughout completely different fields.
The foremost problem lies in getting and prepping the information. Building a picture segmentation dataset calls for annotating heaps of photographs to outline the labels, which is a large activity. This requires a ton of sources.
So, the sport modified when the Segment Anything Model (SAM) got here into the scene. SAM revolutionized this area by enabling anybody to create segmentation masks for his or her knowledge with out counting on labeled knowledge.
In this text, I’ll information you thru understanding SAM, its workings, and how one can put it to use to make masks. So, prepare together with your cup of espresso as a result of we’re diving in! ☕
Prerequisites:
The conditions for this text embody a fundamental understanding of Python programming and a basic information of machine studying.
Additionally, familiarity with picture segmentation ideas, laptop imaginative and prescient, and knowledge annotation challenges would even be helpful.
What is the Segment Anything Model?
SAM is a Large Language Model that was developed by the Facebook analysis staff (Meta AI). The mannequin was skilled on a large dataset of 1.1 billion segmentation masks, the SA-1B dataset. The mannequin can generalize nicely to unseen knowledge as a result of it’s skilled on a really various dataset and has low variance.
SAM can be utilized to section any picture and create masks with none labeled knowledge. It is a breakthrough, as no totally automated segmentation was attainable earlier than SAM.
What makes SAM distinctive? It is a first-of-its-kind, promptable segmentation mannequin. Prompts mean you can instruct the mannequin in your desired output via textual content and interactive actions. You can present prompts to SAM in a number of methods: Points, Bounding Boxes, texts, and even base masks.
How Does SAM Work?
SAM makes use of a transformer-based structure, like most Large Language Models. Let’s have a look at the stream of information via completely different elements of SAM.
Image Encoder: When you present a picture to SAM, it’s first despatched to the Image Encoder. True to its identify, this element encodes the picture into vectors. These vectors symbolize the low-level (edges, outlines) and high-level options like object shapes and textures extracted from the picture. The encoder here’s a Vision Transformer (ViT), which has many benefits over conventional CNNs.
Prompt Encoder: The immediate enter the consumer provides is transformed to embeddings by the immediate encoder. SAM makes use of positional embeddings for factors, bounding field prompts, and textual content encoders for textual content prompts.
Mask Decoder: Next, SAM maps the extracted picture options and immediate encodings to generate the masks, which is our output. SAM will generate 3 segmented masks for each enter immediate, offering the customers with selections.
Why use SAM?
With SAM, you may skip the costly setup often wanted for AI, and nonetheless get quick outcomes. It works nicely with all types of information, like medical or satellite tv for pc photographs, and matches proper into the software program you already use for fast detection duties.
You additionally get instruments tailor-made for particular jobs like picture segmentation, and it’s simple to work together with, whether or not you are coaching it or asking it to research knowledge. Plus, it’s faster than older programs like CNNs, saving you each money and time.
How to Install and Set up SAM
Now that you understand how SAM works, let me present you easy methods to set up and set it up. The first step is to put in the bundle in your Jupyter pocket book or Google Colab with the next command:
pip set up 'git+https://github.com/facebookresearch/segment-anything.git'
/content material Collecting git+https://github.com/facebookresearch/segment-anything.git Cloning https://github.com/facebookresearch/segment-anything.git to /tmp/pip-req-build-xzlt_n7r Running command git clone --filter=blob:none --quiet https://github.com/facebookresearch/segment-anything.git /tmp/pip-req-build-xzlt_n7r Resolved https://github.com/facebookresearch/segment-anything.git to commit 6fdee8f2727f4506cfbbe553e23b895e27956588 Preparing metadata (setup.py) ... finishedThe subsequent step is to obtain the pre-trained weights of the SAM mannequin you wish to use.
You can select from three choices of checkpoint weights: ViT-B (91M), ViT-L (308M), and ViT-H (636M parameters).
How do you select the best one? The bigger the variety of parameters, the longer the time wanted for inference, that’s masks era. If you will have low GPU sources and quick inference, go for ViT-B. Otherwise, select ViT-H.
Follow the beneath instructions to arrange the mannequin checkpoint path:
!wget -q https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
CHECKPOINT_PATH='/content material/weights/sam_vit_h_4b8939.pth'
import torch
DEVICE = torch.system('cuda:0' if torch.cuda.is_available() else 'cpu')
MODEL_TYPE = "vit_h"The mannequin weights are prepared! Now, I’ll present you completely different strategies via which you’ll be able to present prompts and generate masks within the upcoming sections. 🚀
How SAM Can Generate Masks Automatically
SAM can robotically section the complete enter picture into distinct segments with out a particular immediate. For this, you should utilize the SamAutomaticMaskGenerator utility.
Follow the beneath instructions to import and initialize it with the mannequin kind and checkpoint path.
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
sam = sam_model_registry[MODEL_TYPE](checkpoint=CHECKPOINT_PATH).to(system=DEVICE)
mask_generator = SamAutomaticMaskGenerator(sam)For instance, I’ve uploaded a picture of canines to my pocket book. It will likely be our enter picture, which must be transformed into RGB (Red-Green-Blue) pixel format to be enter to the mannequin.
You can do that utilizing the OpenCV Python bundle after which use the generate() operate to create a masks, as proven beneath:
# Import opencv bundle
import cv2
# Give the trail of your picture
IMAGE_PATH= '/content material/canine.png'
# Read the picture from the trail
picture= cv2.imread(IMAGE_PATH)
# Convert to RGB format
image_rgb = cv2.cvtColor(picture, cv2.COLOR_BGR2RGB)
# Generate segmentation masks
output_mask = mask_generator.generate(image_rgb)
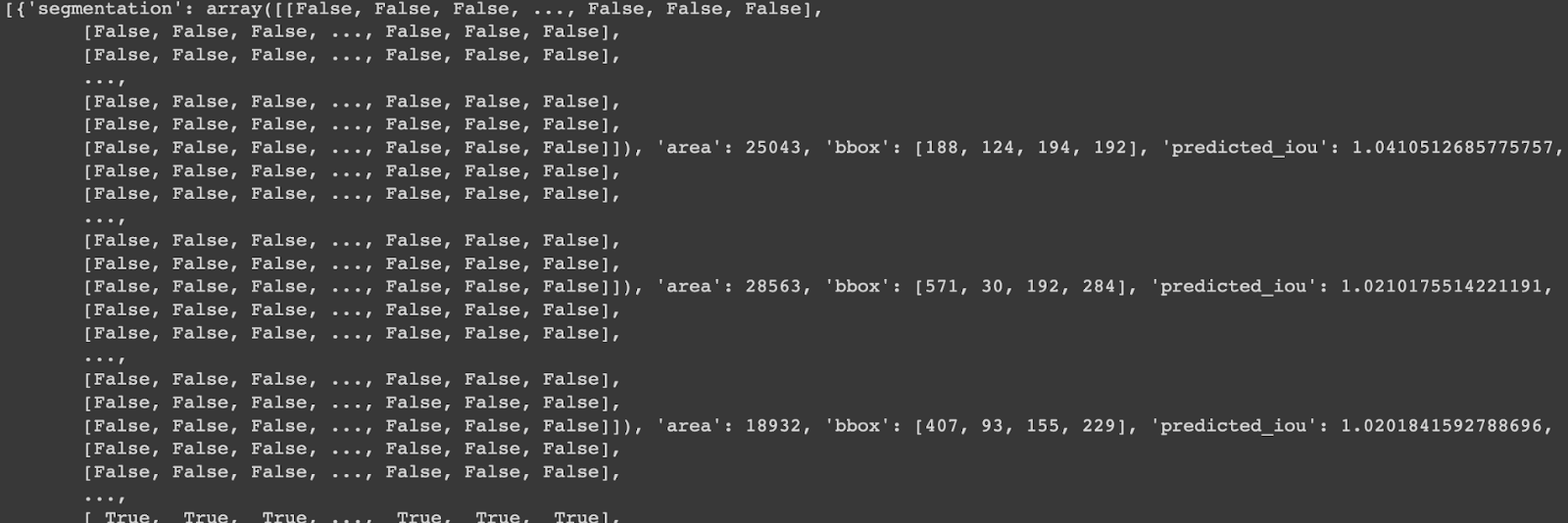
print(output_mask)
The generated output is a dictionary with the next foremost values:
Segmentation:An array that has a masks formspace:An integer that shops the realm of the masks in pixelsbbox:The coordinates of the boundary field [xywh]Predicted_iou:IOU is an analysis rating for segmentation
So how can we visualize our output masks?
Well, it is a easy Python operate that may take the dictionary generated by SAM as output and plot the segmentation masks with the masks form values and coordinates.
# Function that inputs the output and plots picture and masks
def show_output(result_dict,axes=None):
if axes:
ax = axes
else:
ax = plt.gca()
ax.set_autoscale_on(False)
sorted_result = sorted(result_dict, key=(lambda x: x['area']), reverse=True)
# Plot for every section space
for val in sorted_result:
masks = val['segmentation']
img = np.ones((masks.form[0], masks.form[1], 3))
color_mask = np.random.random((1, 3)).tolist()[0]
for i in vary(3):
img[:,:,i] = color_mask[i]
ax.imshow(np.dstack((img, masks*0.5)))Let’s use this operate to plot our uncooked enter picture and segmented masks:
_,axes = plt.subplots(1,2, figsize=(16,16))
axes[0].imshow(image_rgb)
show_output(sam_result, axes[1])
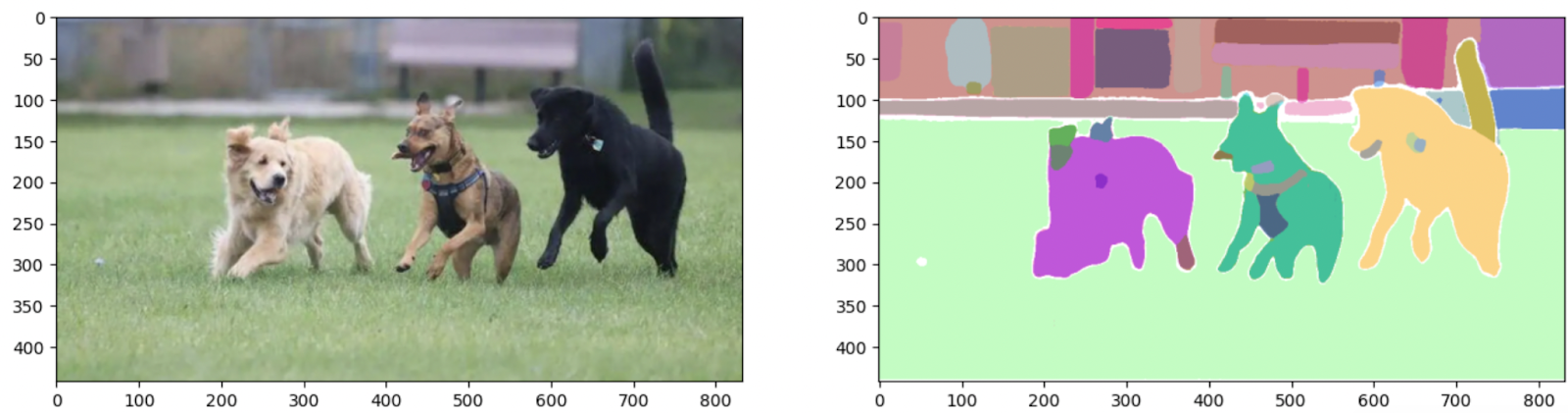
As you may see, the mannequin has segmented each object within the picture utilizing a zero-shot methodology in a single single go! 🌟
How to Use SAM with Bounding Box Prompts
Sometimes, we might wish to section solely a particular portion of a picture. To obtain this, enter tough bounding containers to determine the item throughout the space of curiosity, and SAM will section it accordingly.
To implement this, import and initialize the SamPredictor and use the set_image() operate to go the enter picture. Next, name the predict operate, offering the bounding field coordinates as enter for the parameter field as proven within the snippet beneath. The bounding containers immediate must be within the [X-min, Y-min, X-max, Y-max] format.
# Set up the SAM mannequin with the encoded picture
mask_predictor = SamPredictor(sam)
mask_predictor.set_image(image_rgb)
# Predict masks with bounding field immediate
masks, scores, logits = mask_predictor.predict(
field=bbox_prompt,
multimask_output=False
)
# Plot the bounding field immediate and predicted masks
plt.imshow(image_rgb)
show_mask(masks[0], plt.gca())
show_box(bbox_prompt, plt.gca())
plt.present()

How to Use SAM with Points as Prompts
What when you want the item’s masks for a sure level within the picture? You can present the purpose’s coordinates as an enter immediate to SAM. The mannequin will then generate the three most related segmentation masks. This helps in case of any ambiguity on the principle object of curiosity.
The first steps are much like what we did in earlier sections. Initialize the predictor module with the enter picture. Next, present the enter immediate as [X,Y] coordinates to the parameter point_coords.
# Initialize the mannequin with the enter picture
from segment_anything import sam_model_registry, SamPredictor
sam = sam_model_registry[MODEL_TYPE](checkpoint=CHECKPOINT_PATH).to(system=DEVICE)
mask_predictor = SamPredictor(sam)
mask_predictor.set_image(image_rgb)
# Provide factors as enter immediate [X,Y]-coordinates
input_point = np.array([[250, 200]])
input_label = np.array([1])
# Predict the segmentation masks at that time
masks, scores, logits = mask_predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True,
)
As we’ve got set the multimask_output parameter as True, there could be three output masks. Let’s visualize it by plotting the masks and their enter immediate.

I’ve additionally printed the self-evaluated IOU scores for every masks. IOU stands for Intersection Over Union and measures the deviation between the item define and masks.
Conclusion
You can construct a tailor-made segmentation dataset in your area by gathering uncooked photographs and using the SAM instrument for annotation. This mannequin has proven constant efficiency, even in tough circumstances like noise or occlusion.
In the upcoming model, they’re making textual content prompts suitable, aiming to boost user-friendliness.
Hope this information proves useful for you!
Thank you for studying! I’m Jess, and I’m an professional at Hyperskill. You can try our ML programs on the platform.