
You learn that proper – you may observe net scraping with out leaving your comfortable place: Google Sheets.
Google Sheets has 5 built-in capabilities that aid you import information from different sheets and different net pages. We’ll stroll via all of them so as from best (most restricted) to hardest (strongest).
Here they’re, and you may click on every perform to skip right down to its devoted part. I’ve made a video as properly that walks via all the things:
Section Shortcuts
Here’s the Google Sheet we’ll be utilizing to demo every perform.
If you’d wish to edit it, make a replica by choosing File – Make a replica if you open it.

How to make use of the IMPORTRANGE perform
This is the one perform that imports a spread from one other sheet fairly than information from one other net web page. So, for those who’ve bought one other Google Sheet, you may hyperlink the 2 sheets collectively and import the info you want from one sheet into the opposite sheet.
For occasion, here is a sheet with a bunch of random Samsung Galaxy information in it.
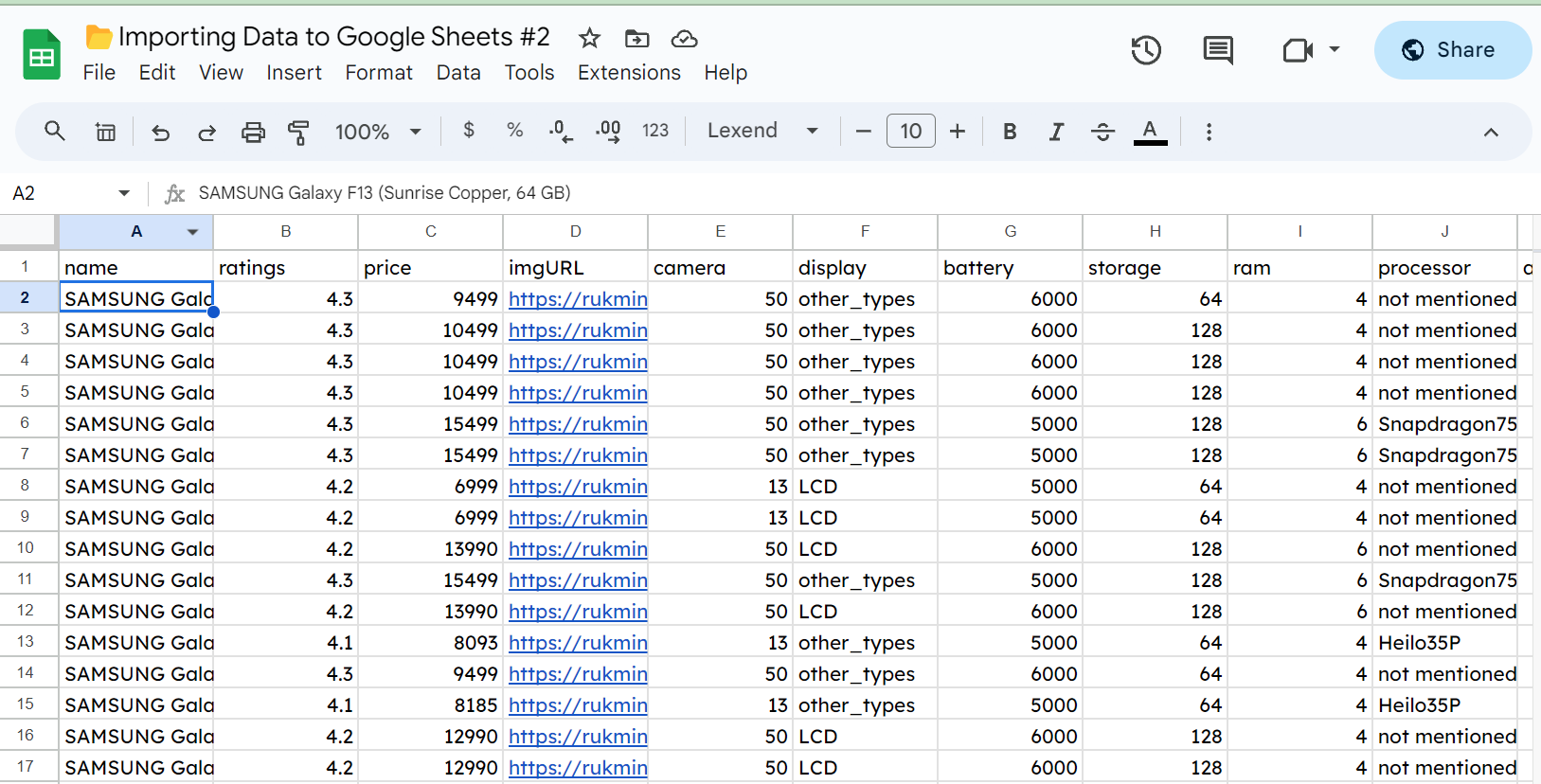
You can see that we now have a couple of hundred rows of information about telephones. If we wish to import this information into one other spreadsheet, we will use IMPORTRANGE(). This is the only to make use of of the 5 capabilities we’ll have a look at. All it wants is a URL for a Google Sheet and the vary we wish to import.
Check out the tab for IMPORTRANGE within the Google Sheet right here, and you may see that in cell A5, we have got the perform =IMPORTRANGE(B4,"information!a1:Ok"). This is pulling within the vary A1:Ok from the information tab of our second spreadsheet whose URL is in cell B4.
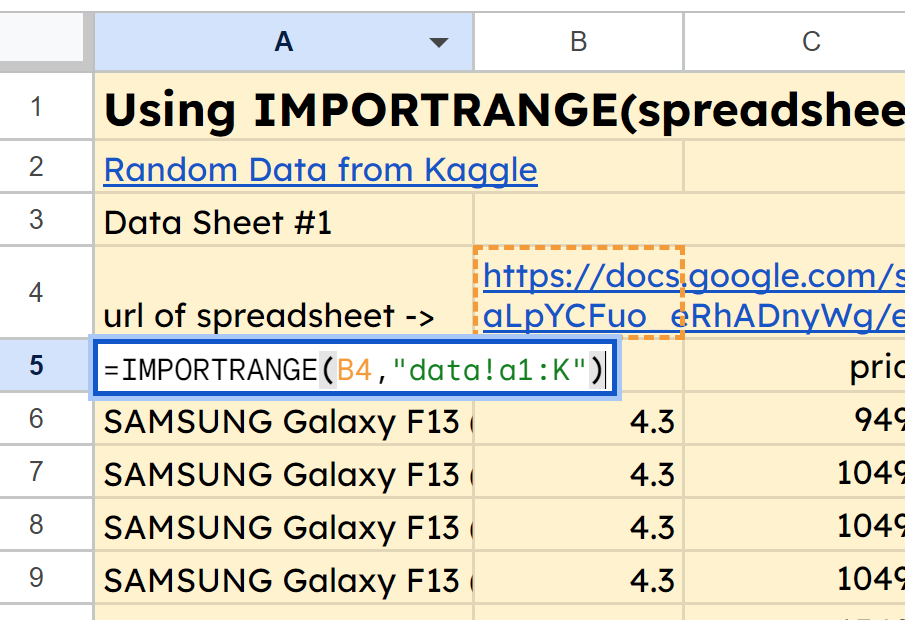
Once your information is pulled into your spreadsheet, you are able to do one in every of two issues.
- Leave it linked via the
IMPORTRANGEperform. This manner, in case your information supply goes to be up to date, you will pull within the up to date information. - Copy and CTRL+SHIFT+V to stick values solely. This manner, you could have the uncooked information in your new spreadsheet and you will not should be depending on one thing altering with the URL down the street.
How to make use of the IMPORTDATA perform
This is fairly easy. It’ll import .csv or .tsv information from wherever on the web. These stand for Comma Separated Values and Tab Separated Values.
.csv is probably the most generally used file sort for monetary information that must be imported into spreadsheets and different applications.
Like IMPORTRANGE, we solely want a pair items of knowledge for IMPORTDATA: the URL the place the file lives, and the delimiter. There’s additionally an non-obligatory variable for locale, however I discovered that it was pointless.
In reality, Google Sheets is fairly sensible – you may depart off the delimiter too, and it’ll normally decipher what sort of information (.csv or .tsv) lives on the URL.
You can see that I’ve discovered a New York authorities information web site the place there lives some profitable lottery quantity information. I’ve put the URL for a .csv file in A5, after which used the perform =IMPORTDATA(A5,",") to tug within the information from the .csv file.

You might alternatively obtain the .csv file after which choose File – Import to herald this information. But within the occasion that you just should not have obtain permissions or just wish to get it straight from a website, IMPORTDATA works nice.
How to make use of the IMPORTFEED perform
This imports RSS feed information. If you are aware of podcasting, you could acknowledge the time period. Every podcast has an RSS feed which is a structured file filled with XML information.
Using the URL for the RSS feed, IMPORTFEED will pull in information a couple of podcast, information article, or weblog from its RSS data.
This is the primary perform that begins to have a couple of extra choices at its disposal, too.
All that is required is the URL of a feed, and it will usher in information from that feed. However, we will specify a couple of different parameters if we like. The choices embody:
- [query]: this specifies which items of information to tug from the feed. We can choose from choices like “feed <sort>” the place sort might be title, description, creator or URL. Same take care of “gadgets <sort>” the place sort might be title, abstract, URL or created.
- [headers]: this may both usher in headers (TRUE) or not (FALSE)
- [num_items]: this may specify what number of gadgets to return when utilizing Query. (The docs state that if this is not specified, all gadgets at present printed are returned, however I didn’t discover this to be the case. I needed to specify a bigger quantity to get again greater than a dozen or so).
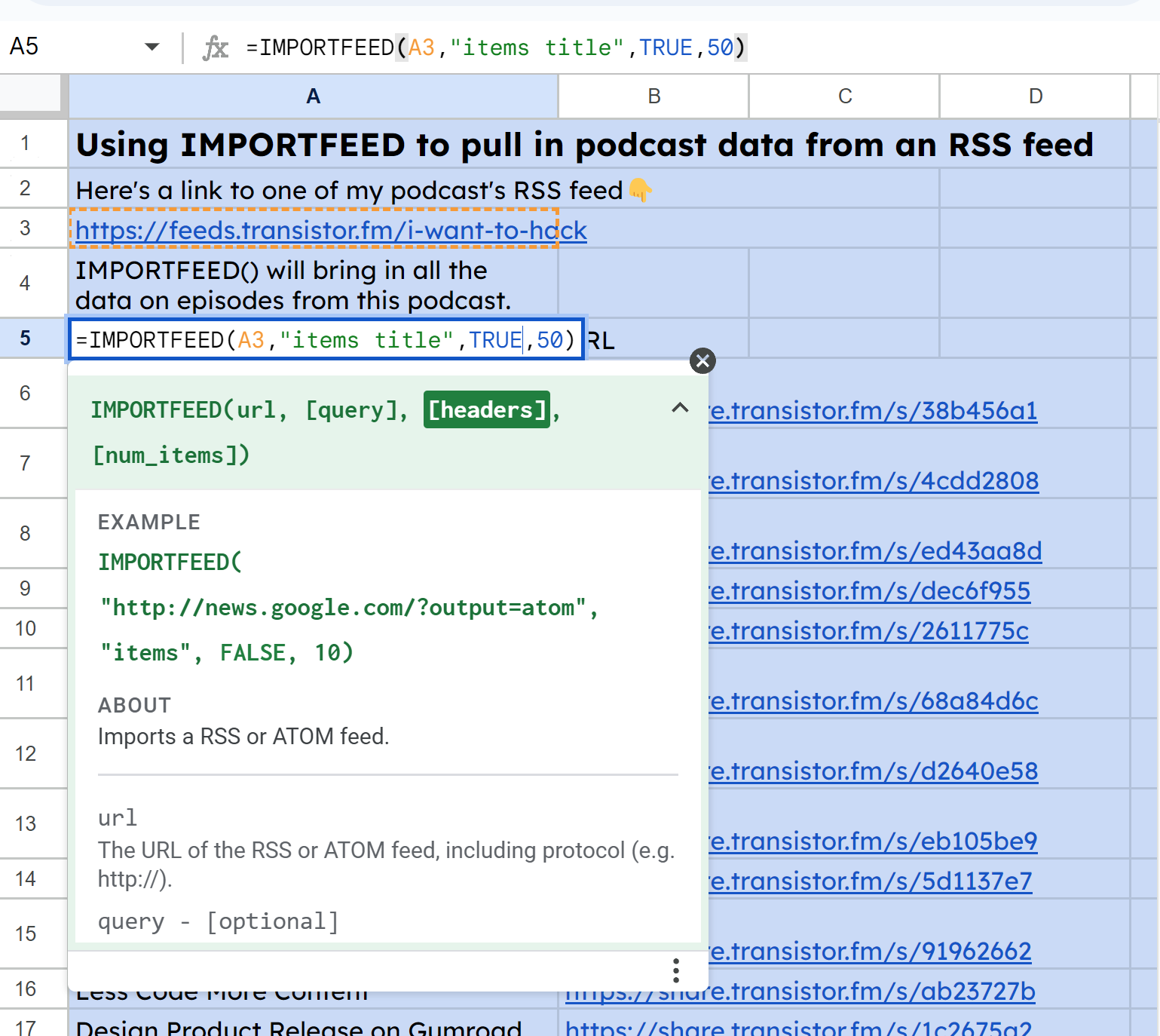
You can see from the screenshots under that I’m querying one in every of my feeds to tug within the episode titles and URLs.
First, to get all of the titles, I used IMPORTFEED(A3, "gadgets title", TRUE, 50:
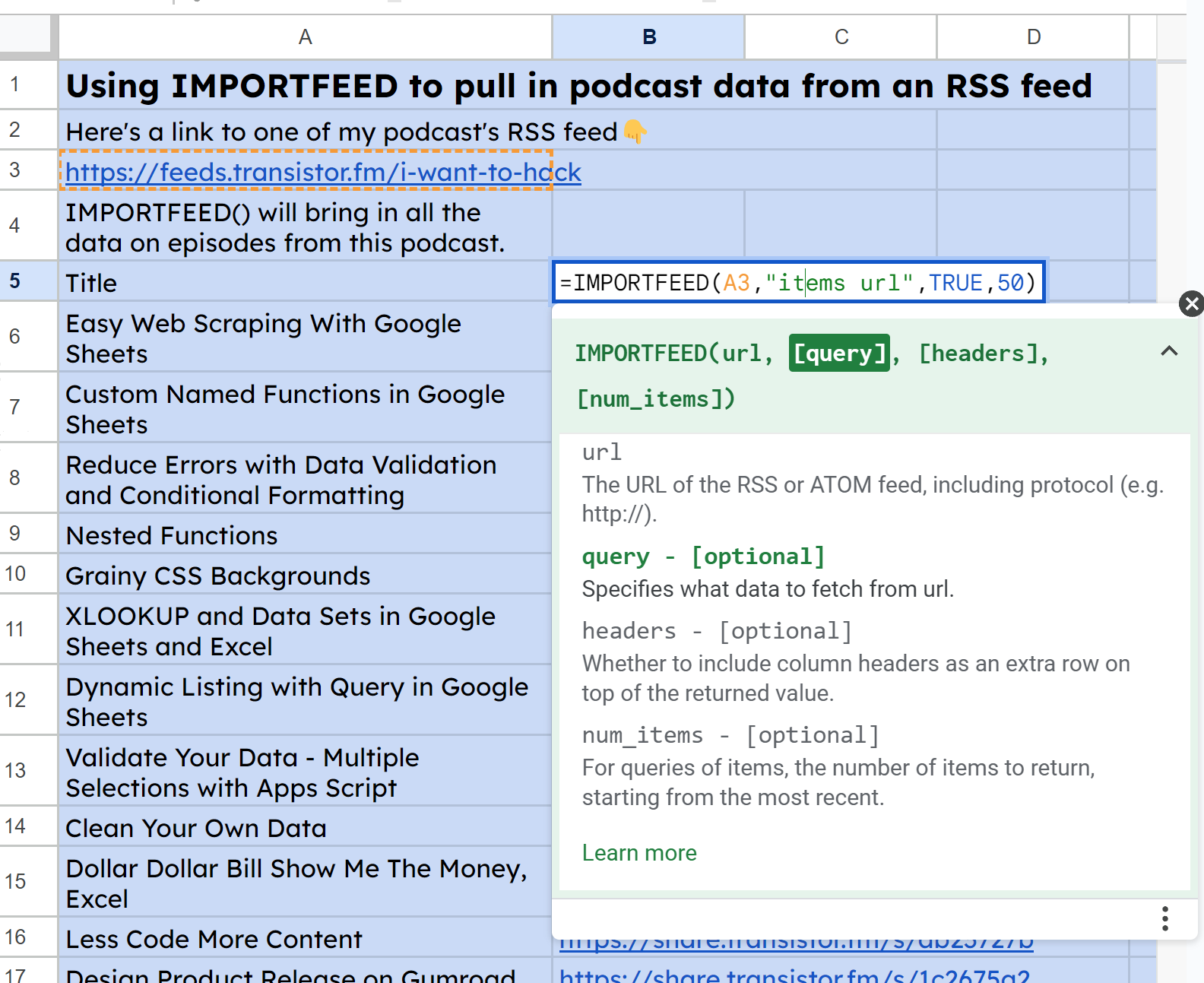
Then, equally for the URLs, I used IMPORTFEED(A3, "gadgets url", TRUE, 50):
How to make use of the IMPORTHTML perform
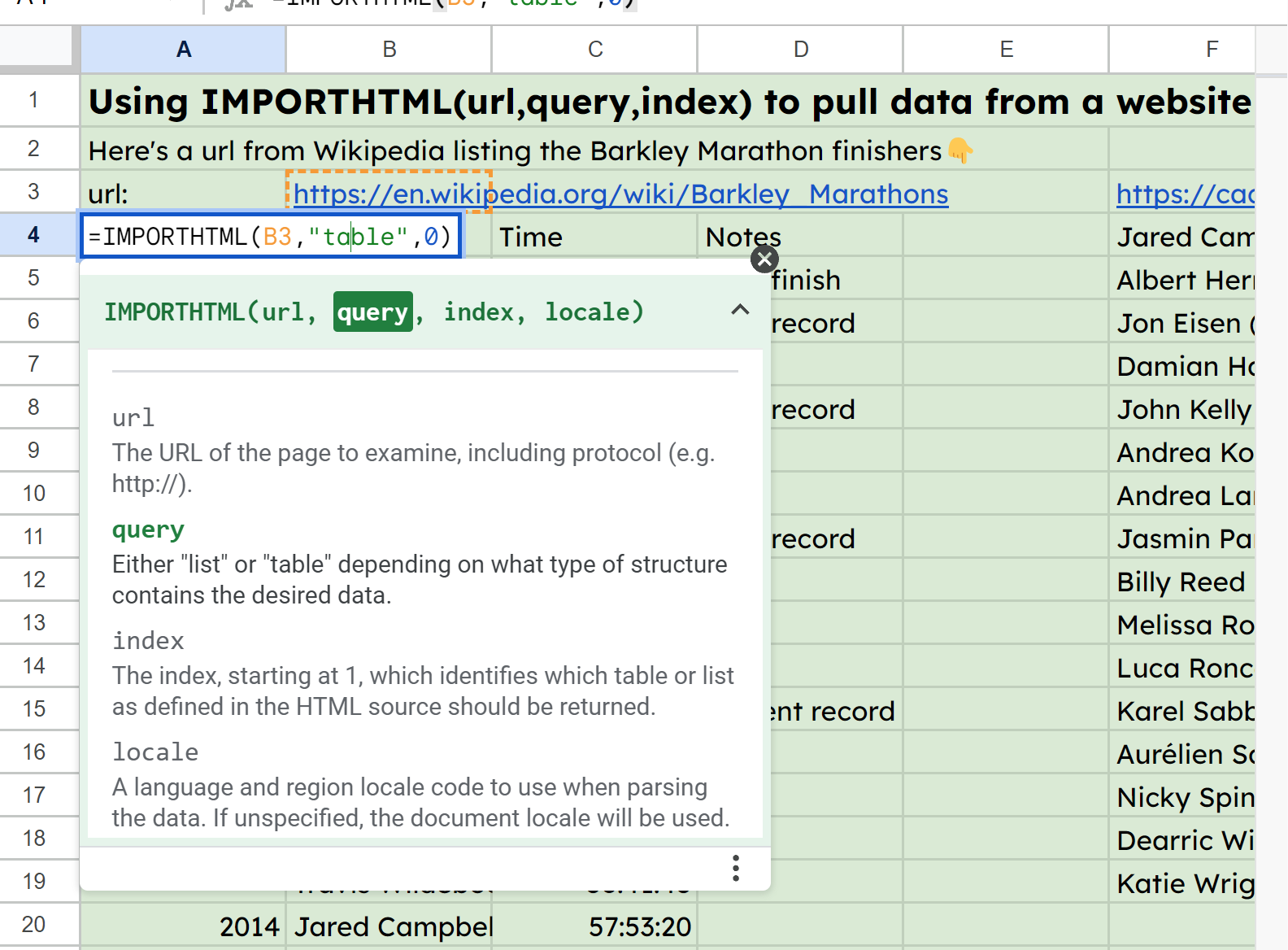
Now we’re stepping into scraping information straight off of a web page. This will take a URL after which a question parameter the place we specify to search for both a “desk” or a “listing”.
This is adopted by an index worth representing which desk or listing to search for if there are a number of on the web page. It is zero listed, so enter zero for those who’re in search of the primary one.
IMPORTHTML seems via the HTML code on a web site for <desk> and <listing> HTML parts.
<!--Here's what a easy desk seems like:-->
<desk>
<thead>
<tr>
<th>desk header 1</th>
<th>desk header 2</th>
</tr>
</thead>
<tbody>
<tr>
<td>desk information row 1 cell1</td>
<td>desk information row 1 cell2</td>
</tr>
<tr>
<td>desk information row 2 cell1</td>
<td>desk information row 2 cell2</td>
</tr>
</tbody>
</desk>
<!--Here's what an ordered listing seems like:-->
<ol>
<li>ordered merchandise 1</li>
<li>ordered merchandise 2</li>
<li>ordered merchandise 2</li>
</ol>
<!--Here's what an unordered listing seems like:-->
<ul>
<li>unordered merchandise 1</li>
<li>unordered merchandise 2</li>
<li>unordered merchandise 3</li>
</ul>In the pattern sheet, I’ve bought the URL for some stats in regards to the Barkley Marathons in cell B3 and am then referencing that in A4‘s perform: =IMPORTHTML(B3,"desk",0).
FYI, freeCodeCamp created ScrapePark as a spot to observe net scraping, so you need to use it for IMPORTHTML and IMPORTXML arising subsequent👇.
How to make use of the IMPORTXML perform
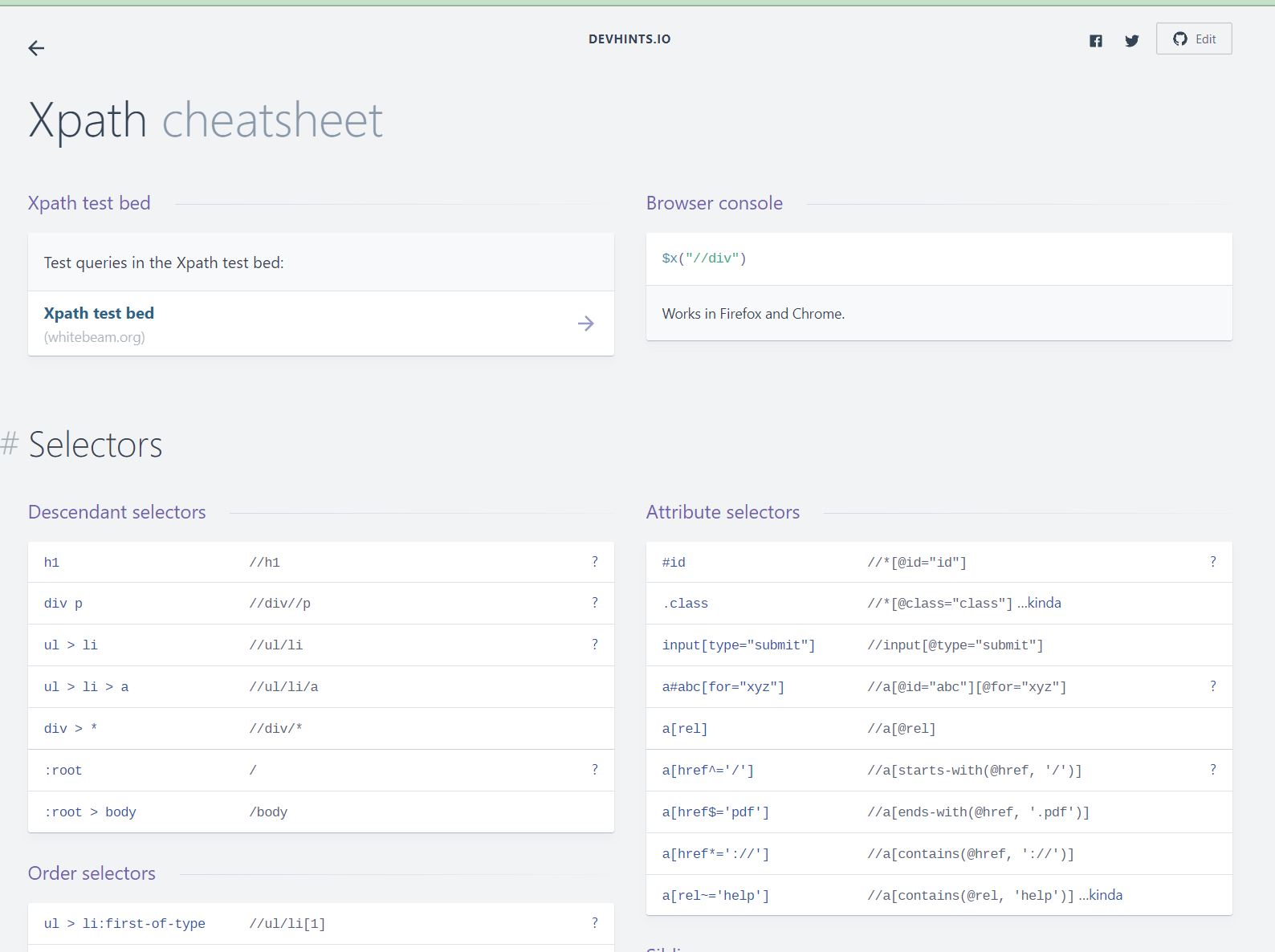
We saved the perfect for final. This will look via web sites and scrape darn close to something we wish it too. It’s sophisticated, although, as a result of as an alternative of importing all of the desk or listing information like with IMPORTHTML, we write our queries utilizing what’s referred to as XPath.
XPath is an expression language itself used to question XML paperwork. We can write XPath expressions to have IMPORTXML scrape every kind of issues from an HTML web page.
There are many assets to search out the correct XPath expressions. Here’s one that I used for this mission.
In the sheet for IMPORTHTML, I’ve a number of examples that I encourage you to click on via and take a look at.
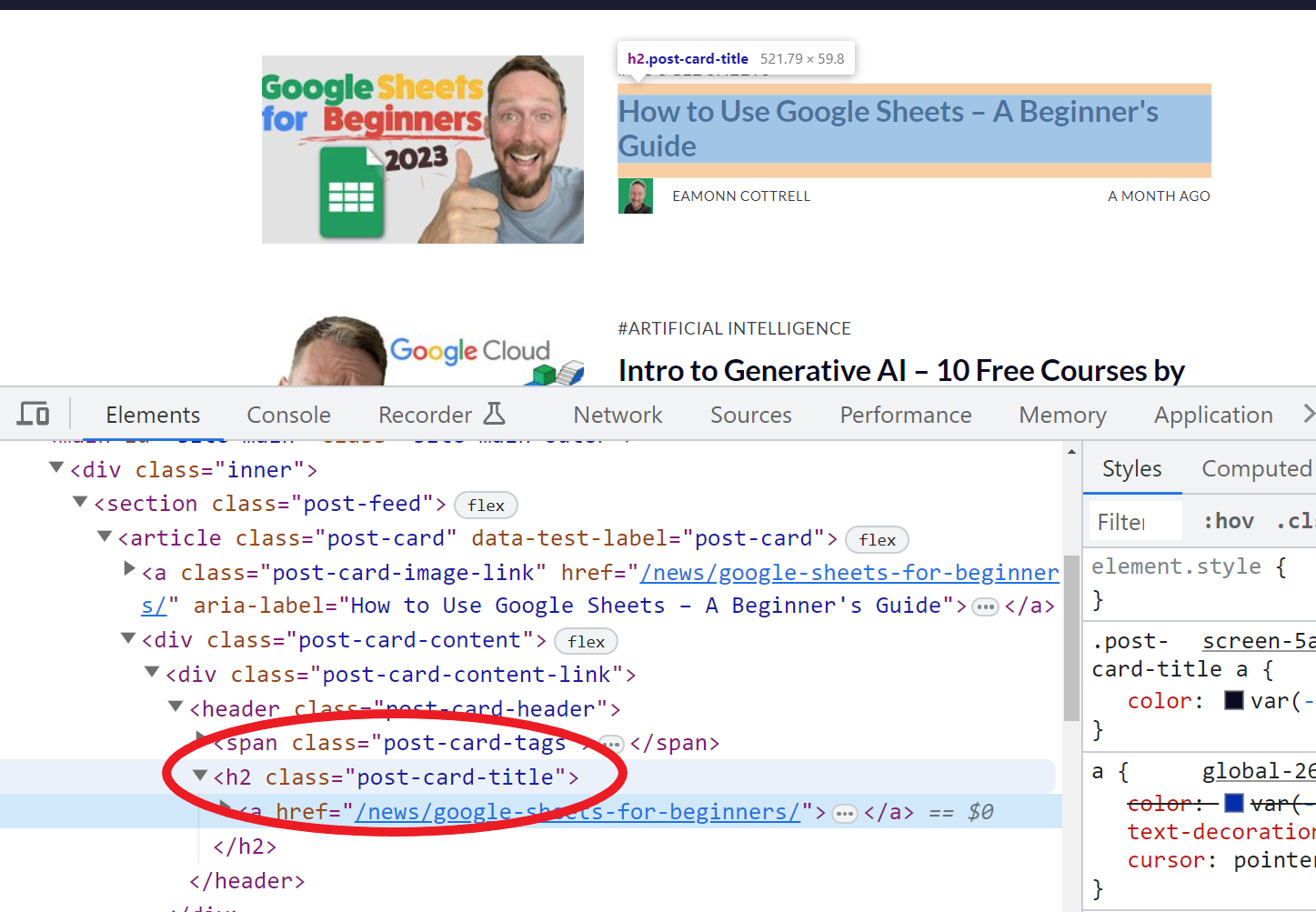
For instance, utilizing the perform =IMPORTXML(A11,"//*[@class="post-card-title"]") permits us to herald all of the titles of my articles as a result of from inspecting the HTML on my creator web page right here, I discovered that all of them have the category post-card-title.
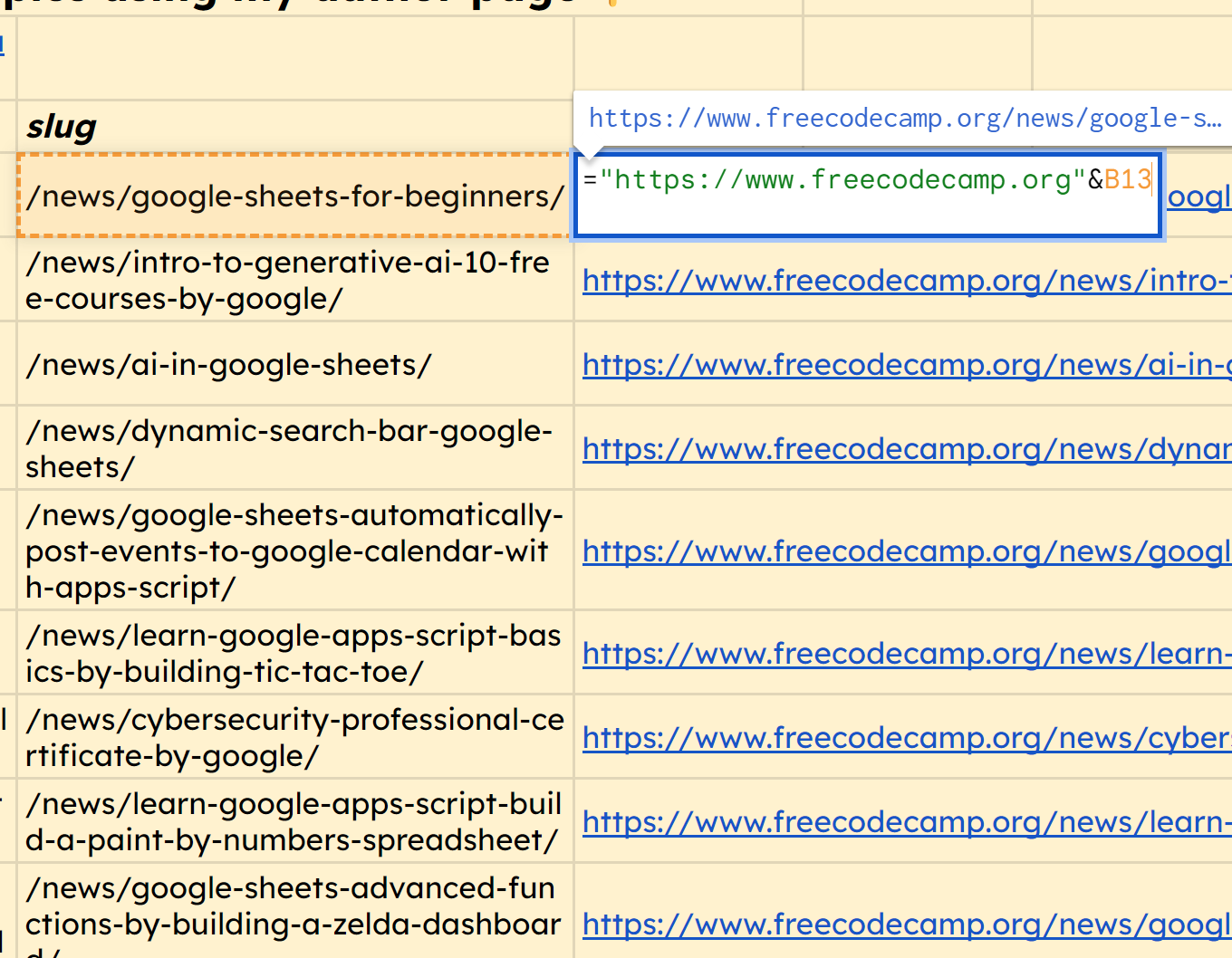
In the identical manner, we will use the perform =IMPORTXML(A11,"//*[@class="post-card-title"]//a/@href") to seize the URL slug of every of these articles.
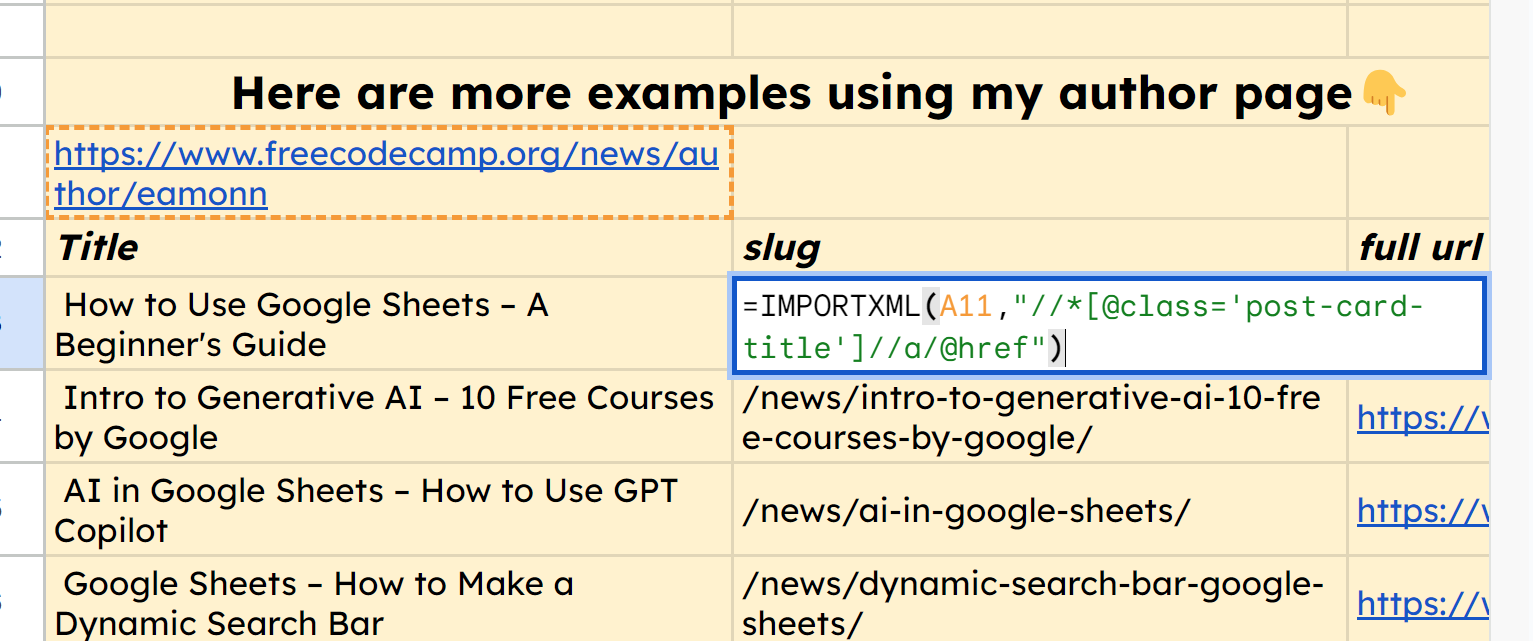
You’ll discover that it does deliver within the full URL, in order a bonus, we will merely prepend the area to every of those. Here’s the perform for the primary row which we will drag right down to get all these correct URLs: ="https://www.freecodecamp.org"&B13
Follow Me
I hope this was useful for you! I realized lots myself, and loved placing the video collectively.
You can discover me on YouTube: https://www.youtube.com/@eamonncottrell
And, I’ve bought a publication right here: https://got-sheet.beehiiv.com/