
Ok-means clustering is a strong approach that may assist you uncover hidden patterns and groupings in your datasets. Let’s have a look at the way it works.
Ok-means clustering is a fundamental however highly effective instrument in information science. It has modified the best way we have a look at and perceive giant datasets.
In this text, we’ll study what Ok-means clustering is, the way it works, what it’s used for, and a few issues it might need. This information is useful and simple to know, whether or not you’re studying about information science or simply considering it.
Basics of Clustering
Clustering is a option to put comparable information factors into teams. It helps us discover patterns and shapes in information, which may be very helpful in areas like advertising and biology.
It’s a sort of ‘unsupervised studying’, that means the information varieties its personal teams with out us realizing the solutions beforehand.
There are many sorts of clustering strategies like Hierarchical, Density-based, Distribution-based, and Partitioning strategies. Ok-means falls into the class of “partitioning strategies”.
What is Ok-Means Clustering?
Ok-means clustering is a option to break up information into teams, or ‘clusters’.
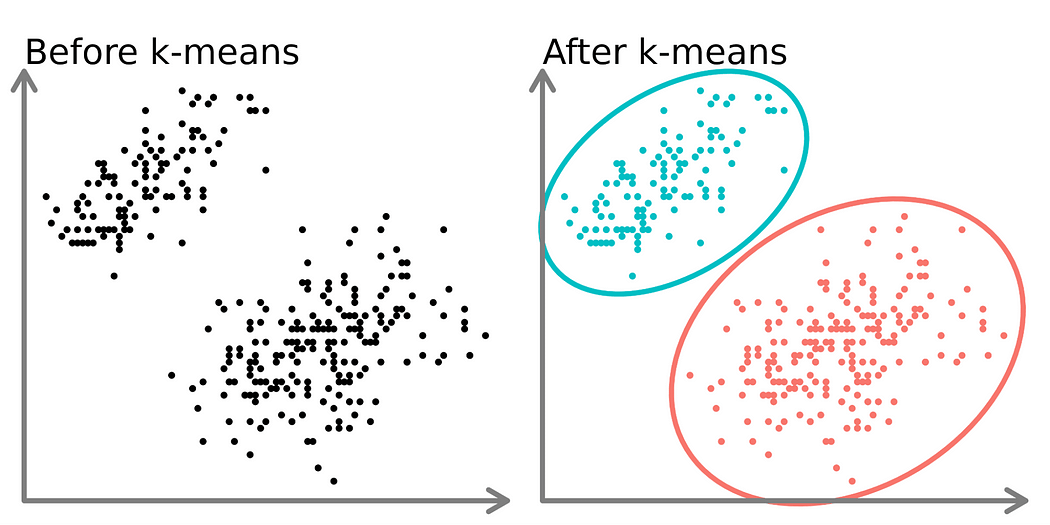
We resolve what number of teams we wish, referred to as ‘Ok’. The goal is to make objects in every group as comparable as doable whereas making the teams completely different from one another.
Ok-means often makes teams which might be about the identical dimension. This is completely different from hierarchical clustering, which may make teams of various sizes.
How the Ok-means Algorithm Works
Ok-means is fashionable as a result of it’s a easy but good manner of clustering information. Here’s the way it works.
A cluster is a gaggle of knowledge factors which might be grouped collectively as a result of they’re comparable. You will select a quantity, okay, which is the variety of central factors, referred to as centroids, that you really want in your information.
A centroid is a central spot that stands in the course of a cluster. Each information level is positioned into one among these clusters. This is finished by minimizing the whole distance inside every cluster.
In easy phrases, the Ok-means algorithm picks okay centroids, after which assigns every information level to the closest cluster. The aim is to maintain these central factors, or centroids, as shut collectively as doable.
Here, the time period ‘means’ in Ok-means is about discovering the common or the centroid of the information.
Here is a step-by-step method:
- Pick the Number of Groups (Ok): First, resolve what number of teams you need, referred to as ‘Ok’. You can select this primarily based on what you already know or use strategies just like the elbow technique.
- Start with Centroids: Choose Ok factors out of your information randomly as beginning factors, referred to as centroids.
- Group Data Points: Put every level in your information into the closest group, primarily based on how shut it’s to the centroids.
- Update Centroids: Change every group’s centre level to the common of all of the factors in that group.
- Keep Going Until It’s Just Right: Repeat steps 3 and 4 till the teams don’t change any extra.
Picking the suitable quantity for Ok is vital. If you might have too many teams, it would get too sophisticated. If you might have too few, it may be too easy.
If you need to see how this works in code, right here is a straightforward instance:
from sklearn.cluster import OkMeans
import matplotlib.pyplot as plt
import numpy as np
# Step 1: Generate random information
np.random.seed(0)
x = -2 * np.random.rand(100, 2) # Generate random factors round (-2, -2)
x1 = 1 + 2 * np.random.rand(50, 2) # Generate random factors round (3, 3)
x[50:100, :] = x1 # Combine the 2 units of factors
# Step 2: Visualize the information (unclustered)
plt.scatter(x[:, 0], x[:, 1], s=50, c="b")
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
plt.present()
# Step 3: Apply OkMeans clustering
kmeans = OkMeans(n_clusters=2) # Initialize OkMeans with 2 clusters
kmeans.match(x) # Fit the mannequin to the information
# Step 4: Get the coordinates of the cluster facilities and the cluster labels
centroids = kmeans.cluster_centers_ # Centroids of the clusters
labels = kmeans.labels_ # Labels of every level
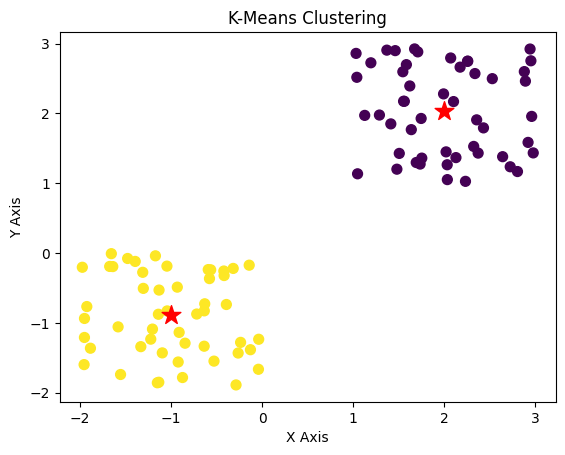
# Step 5: Visualize the clustered information
plt.scatter(x[:, 0], x[:, 1], s=50, c=labels, cmap='viridis') # Plot information factors with cluster shade
plt.scatter(centroids[:, 0], centroids[:, 1], s=200, c="crimson", marker="*") # Plot centroids
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
plt.title('Ok-Means Clustering')
plt.present()Here is the ultimate end result after clustering.
Where Do We Use Ok-Means Clustering?
Ok-means clustering is utilized in many areas. Let’s have a look at a couple of of them:
Market Segmentation
Ok-means clustering is a instrument companies use to study their prospects. It teams prospects by purchases, pursuits, or location.
It is helpful in retail and e-commerce for making good advertising methods together with recommending comparable merchandise merchandise. A very good instance is Amazon’s ideas of associated objects after you make a purchase order.
This technique makes customer support and product promotion simpler. It helps companies tailor their choices to completely different buyer wants, bettering gross sales and buyer satisfaction.
Image Compression and Processing
The Ok-means algorithm is vital for working with digital photos, particularly on the subject of making them smaller. It does this by by grouping comparable colors collectively and changing them with a single color.
When there are fewer colors, the picture file turns into smaller, which saves space for storing and makes it simpler to ship and use the picture. This course of doesn’t simply make the picture file smaller – it additionally makes the picture easier for computer systems to research.
This color discount is useful in areas like medical imaging. Doctors usually use detailed scans like MRIs to diagnose and deal with diseases. These scans present numerous tiny particulars, and generally there’s an excessive amount of data. By utilizing Ok-means to simplify the picture, medical doctors can extra simply see the vital components.
Document Clustering for Information Retrieval
Ok-means clustering may also help handle piles of on-line data. It works by placing comparable paperwork into teams. This is helpful for engines like google, digital libraries and different giant scale doc databases.
Imagine a web-based library with hundreds of thousands of articles. Ok-means may also help by sorting these articles into associated clusters. This may also help engines like google seek for related content material shortly as an alternative of going by each single article within the database.
When you’re on the lookout for one thing particular, Ok-means makes it simpler and sooner to seek out.
Anomaly Detection in Network Security
In community safety, Ok-means clustering is sort of a good guard. It helps safety groups by recognizing uncommon patterns in information visitors that could possibly be indicators of threats.
Here’s the way it works: Normally, information in a community has an everyday sample. Ok-means appears in any respect this information and teams it primarily based on these patterns. But generally, one thing unusual pops up — like surprising spikes in visitors or odd information actions. These could possibly be clues to safety dangers, like hacking makes an attempt.
Ok-means is nice at shortly discovering these odd patterns. It flags information that doesn’t match into ordinary teams. Security groups can then examine these flags to see in the event that they’re actual risks. This fast recognizing is essential as a result of in community safety, responding quick can forestall a number of harm.
Genome analysis
Ok-means clustering is a great tool in gene analysis, particularly for medical research. It types genes into teams that act equally and helps to know genes higher.
This grouping is efficacious in customized medication which appears at an individual’s distinctive genes to resolve on the very best therapy. Ok-means helps by exhibiting which genes are alike. This manner, medical doctors can perceive the remedies that can work effectively for somebody primarily based on their genes.
So, Ok-means isn’t just about grouping genes. It’s a key a part of making medication that’s good for every particular person. It helps medical doctors select remedies that match an individual’s genetic particulars, which is an enormous step ahead in healthcare.
Conclusion
Ok-means clustering is a strong technique for uncovering patterns in information. By grouping comparable objects, it helps in making data-driven choices in numerous fields.
While it has its limitations, its ease of use and effectiveness make it a go-to technique for exploratory information evaluation. Whether you’re a seasoned information scientist or a curious newbie, delving into k-means clustering can open up new views and insights into your information.
Thanks for studying this text. You can be taught extra at https://manishmshiva.com.