
Tracing the historical past of machine creativity

A category of cutting-edge machine studying methods have grow to be extremely adept at producing new pictures (and now, movies) from scratch or from present ones.
This is known as picture synthesis and has grow to be probably the most in style use circumstances for generative AI.
Image synthesis has many purposes, equivalent to…
- Advertising — creating real looking pictures of merchandise or environments
- Computer imaginative and prescient — producing artificial pictures for mannequin coaching
- Digital artwork — creating new graphics, work and images
- Fashion — producing artistic concepts for design and new merchandise

Simply kind some textual content prompts into DALL-E, Stable Diffusion or Midjourney and you may create photo-realistic pictures of individuals and issues that don’t exist.
What a time to be alive.

In this text, I’m going cowl:
- The machine studying methods behind generative AI artwork;
- How DALL-E, Midjourney and Stable Diffusion works;
- The unbelievable issues you are able to do with these instruments proper now.
New to AI and machine studying? Check out my AI explainer article and sister piece on Large Language Models like ChatGPT.
New to Medium? Join right here and acquire limitless entry to one of the best AI & information science articles on the web.
Grab some tea, sit down and let’s dive in!
Over the previous decade, numerous appropriate ML methods have been developed for picture synthesis. These primarily fall into 4 classes:
- Generative Adversarial Networks (GAN)
- Variational Auto-Encoders (VAE)
- Flow fashions
- Diffusion fashions.

All of those strategies contain coaching a mannequin on a big dataset of pictures, which then learns to generate new pictures related in content material and magnificence to wthose within the coaching set.

And — maybe not surprisingly — these totally different approaches every have their execs and cons. These will be summarised by the generative studying trilemma, which describe the challenges of attaining three conflicting targets — a three-way trade-off between:
- High high quality samples — the generated pictures are nice and resemble the pictures that the mannequin was educated on.
- Fast sampling — the mannequin can generate pictures shortly. Current AI platforms like DALL-E, Midjourney and Stable Diffusion at the moment take lower than a minute to crank out your prompt-driven artwork items!
- Mode protection & range — the mannequin can generate a variety of numerous pictures that cowl all variations of the picture distribution, as a substitute of being biased in direction of sure samples. For instance, an AI educated on a dataset of people ought to be capable of generate individuals of all totally different races and genders (protection) and produce variations inside every of them (range).

Progress on methods is shifting quick. Very quick.
The present state-of-the-art method is the usage of secure diffusion fashions, which is only a rebranding of latent diffusion fashions utilized to excessive decision pictures whereas utilizing CLIP as a text-encoder.
These fashions retain the superior efficiency of diffusion fashions over GANs for picture synthesis whereas ameliorating well-known points of coaching GANs.
If quite a lot of this sounds complicated, let me begin from the start!
Generative Adversarial Networks (GAN)
Contemporary picture synthesis took off thanks GANs, which have been launched by Ian Goodfellow and his colleagues of their 2014 paper “Generative Adversarial Networks”.
At the time, Goodfellow was a PhD scholar on the University of Montreal beneath Yoshua Bengio, considered one of many ‘godfathers of AI’.
This work on GAN has been recognised as a big breakthrough in deep studying, and Goodfellow has since grow to be a number one determine within the AI analysis neighborhood.
In supervised studying, a deep studying mannequin learns to map the enter to the output. During every iteration, the loss is calculated and the parameters are up to date utilizing backpropagation.
For imaging, that is helpful for picture classification the place you wish to recognise and categorise issues.
Generative AI modelling is a kind of unsupervised machine studying, the place the objective is to be taught the underlying sample — or illustration — of the picture information, in order that we are able to generate new pictures with new and assorted properties.
These so-called deep generative fashions fall beneath two varieties: express probability fashions and implicit probability fashions.
Explicit fashions mannequin the likelihood distribution of the coaching information immediately, whereas implicit fashions be taught the statistical properties of the information to generate new pictures with out explicitly needing the coaching information’s likelihood distribution.
An instance of an express mannequin is linear regression, which assumes the goal variable is normally-distributed round a linear mixture of its options.
A GAN mannequin, however, is an implicit probability mannequin that generate new pictures from the statistical properties of the information.
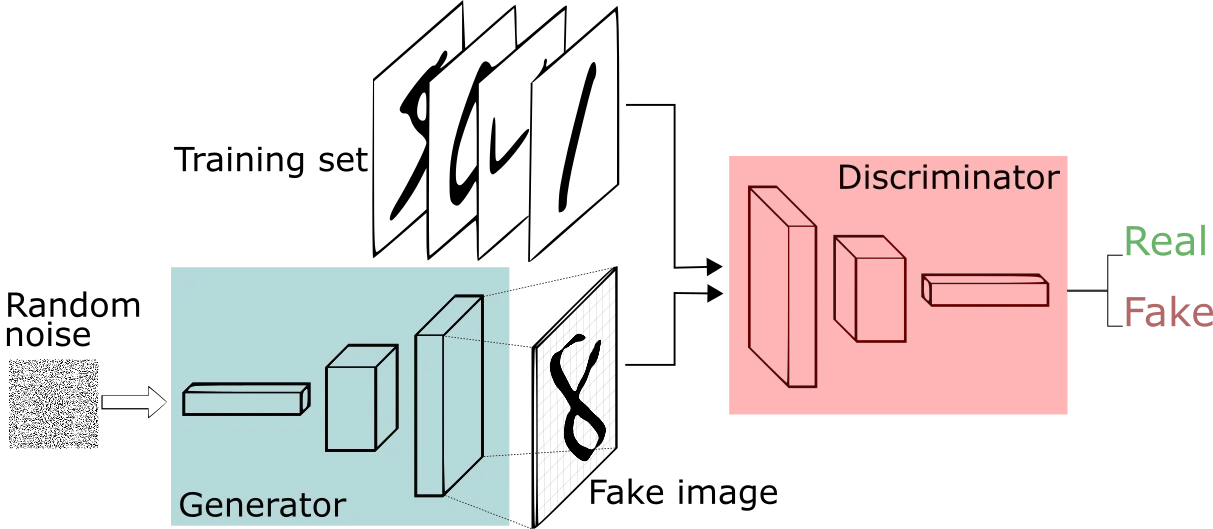
Specifically, two neural networks — a ‘generator’ and a ‘discriminator’ — are educated to compete with one another in a zero-sum recreation to discriminate between true and false pictures.
The generator learns to generate believable information.
The discriminator learns to discriminate whether or not the pictures spun up by the generator belongs to the coaching dataset or not, and penalises its adversary, the generator, for producing implausible outcomes.
Both networks are educated concurrently in a steady suggestions loop, with the discriminator making an attempt to categorise actual and faux pictures accurately, and the generator making an attempt to idiot its mate into classifying its pretend pictures as actual.
What a riot!
The discrimination’s selections after every batch of pictures then prompts the generator to replace its weights via backpropagation.
Through this aggressive adversarial course of, the generator learns to create more and more real looking and convincing pictures to try to idiot the discriminator, whereas the discriminator learns to enhance its means to differentiate actual from pretend pictures.
A rapidly-escalating arms race between two machines.
From a consumer perspective, the enter for GANs are sometimes a random noise vector that’s fed into the generator, which is then reworked into an artificial picture that resembles the coaching information.
To adapt the community to just accept textual content prompts — required for text-to-image generative AI merchandise like DALL-E, the GAN is educated on a dataset of paired textual content and picture examples and learns to generate pictures which can be in step with the enter textual content descriptions.
As Google has identified, GANs do undergo a number of points throughout coaching.
- Failure to converge. This is a standard downside with GANs, the place the 2 competing neural networks — which grow to be higher at era and discrimination over time — in the end fail to converge to an equilibrium state that will herald the top of the coaching. As a outcome, we find yourself with the generator and discriminator networks swinging about in an unstable loop perpetually.
- Mode collapse. This happens when the generator lazily learns to generate the identical output. This may appear to be a great indication of coaching progress (has the generator reached its peak powers?!), when in actuality the discriminator is slowed down in an area minimal and may’t discriminate between an actual picture and the generator’s output.
- Vanishing gradients. If your discriminator is just too good, the generator coaching can grind to a halt. In this case, the masterful discriminator passes little or no data again to the generator, so that in backpropagation, an already small gradient on the ultimate layer shrinks to grow to be smaller and smaller (because the chain rule for differentiation has a multiplicative impact on gradients) till it successfully vanishes after we hit the preliminary layer. As a outcome, the weights on the generator don’t change and coaching successfully stops.
Cue enter: diffusion fashions.
Diffusion Models
Diffusion fashions have lately proven a exceptional efficiency in picture era duties.
In 2021, OpenAI researchers revealed a paper, “Diffusion Models beat GANs on picture synthesis”, which helped set the groundwork for the migration of DALL-E’s GAN-based structure in direction of a diffusion-based mannequin utilized in DALL-E 2.
Diffusion fashions at the moment are extensively considered superior to GANs for picture synthesis. They can produce extra numerous pictures and have been confirmed to not undergo from mode collapse, as a result of their means to protect the ‘semantic construction’ of the information.
In the context of generative AI, a ‘diffusion mannequin’ refers to a particular kind of mannequin often known as a Diffusion Probabilistic Model (DPM). See right here, right here, right here, right here and right here for particulars.
In quick, DPMs generate pictures by iteratively including noise to the preliminary picture to regularly generate a brand new picture. The means of including noise is managed by a particular diffusion course of, therefore the identify ‘diffusion mannequin’.
To practice a diffusion mannequin, we take a picture (coaching information) and corrupt it by progressively including Gaussian noise. This removes particulars within the information till it turns into indistinguishable from pure noise.

The community is then educated step-by-step to foretell a barely de-noised picture from the earlier one.

By iteratively making use of the diffusion neural community to its personal predictions, we are able to go from a picture of pure noise to a practical noiseless picture — that’s now related however not the identical because the preliminary picture.
Voila, picture synthesis!
Similar to GANs — for picture synthesis, the enter for a diffusion mannequin is often a random noise vector (or a picture with random noise added to it). The vector is then ran via the diffusion course of, whereby the noise is progressively smoothed out by the mannequin to generate a coherent picture. For text-to-image use circumstances — like GANs, the diffusion mannequin will be educated on a dataset of paired textual content and picture examples.
In abstract, GANs and diffusion fashions each generate pictures from noise, however they differ in the best way they generate these pictures. GANs create pictures suddenly, whereas diffusion fashions generate pictures regularly over time.
Diffusion fashions is that they’ll generate pictures with a excessive stage of element and complexity, with the trade-off being that coaching is computationally costly, because the diffusion (sampling) course of iteratively feeds a full-sized picture to the community to get the ultimate outcome, just like the cat image above.
This means coaching is gradual with a necessity for many reminiscence for all these intermediate pictures when the whole diffusion steps and the picture dimension is giant.
Meanwhile, GANs can generate pictures shortly and are sometimes used for producing pictures in real-time purposes.
Current state-of-the-art: CLIP + LDMs = “secure diffusion”
Major progress has been made lately to buffer up the weaknesses of DPMs whereas retaining their class-leading picture synthesis efficiency, leading to latent diffusion fashions (LDMs) utilizing CLIP image-encodings.
These are often known as secure diffusion fashions, that are at the moment the state-of-the-art generative AI mannequin for picture synthesis.

Note that this shouldn’t be conflated with the AI product Stable Diffusion — which occurs to make use of a secure diffusion mannequin. More on that later!
Let’s unpack issues a bit.
In Dec 2021, Rombach and Ommer et al. revealed a paper that proposed migrating the diffusion course of of coaching a DPM onto a compressed latent illustration of the coaching picture.
In machine studying, latent variables seize the underlying important components and options that outline a specific picture. instance is Principal Component Analysis (PCA) in unsupervised studying that goals to determine latent variables (‘precept elements’) that may seize the information in a decrease dimension with fewer variables.
These concepts have resulted in latent diffusion fashions, the place the full-sized picture is first transformed right into a compressed lower-dimensional latent information, earlier than having the standard diffusion course of regularly including noise after which iteratively eradicating it to generate a high-quality picture.

As the scale of the latent information is way smaller than the unique pictures, the denoising course of is way sooner, which addresses one of many principal pitfalls befalling DPMS — sloth-like coaching instances.
Overall, an LDM is an software of diffusion processes within the latent area as a substitute of pixel area whereas incorporating the semantic suggestions from the Transformer fashions.
In the identical 12 months, OpenAI researchers constructed a neural community known as Contrastive Language-Image Pre-training (CLIP) that learns the connection between the visible and textual representations of an object.

The enter for CLIP is a pair of picture and textual content prompts, that are first processed into a picture embedding and a textual content embedding. The former is a vector of numbers that seize the options of the picture, whereas the later is (additionally) a vector of numbers that seize the which means of the textual content.
These two embeddings are then mixed to kind a joint illustration of the picture and textual content, which captures the semantic which means of each the picture and textual content, and may then be used for quite a lot of downstream duties, equivalent to classifying pictures and textual content, detecting objects inside pictures, and retrieving pictures semantically-semilar to a given textual content immediate.
In Apr 2022, OpenAI researchers proposed in a paper the concept of chaining CLIP with LPMs.
The outcome was an end-to-end mannequin that retained the strengths of diffusion fashions over GANs, was approach sooner to coach in comparison with DPMs (due to the diffusion course of occurring in latent area), and was capable of rework textual content prompts into unbelievable pictures due to the CLIP embeddings.
In a intelligent bit of promoting, the CLIP + LDM fashions deployed on high-resolution pictures was rebranded inside the business to secure diffusion fashions.
It is the present state-of-the-art method for picture synthesis, with all main mainstream generative AI artwork merchandise having adopted it by Q2 2023.
Mainstream text-to-image generative AI is at the moment dominated by three gamers:

The first model of DALL-E (Jan 2021) employed GANs, earlier than migrating to a secure diffusion mannequin in DALL-E 2 (Sep 2022) off the again of pioneering work by OpenAI’s personal researchers on the prevalence of diffusion fashions and the event of CLIP.
DALL-E 2 comprise two neural community fashions: one (known as Prior) to transform a consumer textual content immediate right into a illustration of an image (picture embeddings) and one other to transform this illustration into an precise picture (known as Decoder).
The coaching works as follows. The Prior is educated to take textual content labels and create CLIP picture embeddings. The Decoder trains on CLIP picture embeddings utilizing a LDM to provide a realized picture.
After coaching, the backend workflow from a DALL-E 2 consumer appears to be like like this:
- The textual content immediate is reworked right into a CLIP textual content embedding.
- Prior reduces the dimensionality of the textual content embedding utilizing PCA.
- Image embedding is created utilizing the textual content embedding.
- Diffusion mannequin transforms the picture embedding into a picture.
- Image is upscaled from 64×64 to 256×256 and at last to 1024×1024 utilizing a Convolutional Neural Network (CNN).
The transition from GAN to secure diffusion was substantial.
DALL-E might solely render AI-created pictures in a cartoonish trend, ceaselessly in opposition to a easy background.
DALL-E 2 is extra adaptable and is ready to generate photo-realistic pictures, showcasing its newfound means to convey numerous concepts to life. The output pictures are bigger and extra detailed.
Moreover, DALL-E is able to in-painting, which lets you intelligently change particular areas inside a picture. For occasion, draw a field round a desk filled with muddle in your picture, kind in pure language directions to vary issues up and let DALL-E work its magic.
But DALL-E 2 takes this to the subsequent stage with out-painting, enabling you to increase an enter picture and construct a world round it. The AI will leverage the information within the preliminary picture — issues just like the vibe, lighting and shadows — to craft an extension past the borders. Here’s a video showcasing DALL-E 2 increasing the canvas of Van Gogh’s well-known The Starry Night.
On an identical vein, Midjourney V5 is a serious leap, capable of generate extraordinarily real looking imagery that’s lots much less ‘creative’ — if that’s what you need. At the identical time, customers are empowered with way more management over the ultimate outcomes, as particulars on the pictures are extremely accountable to consumer prompts.

While Midjourney selected a proprietary enterprise mannequin that takes care of all the things: mannequin improvement, coaching, tweaking and UI, Stable Diffusion embraces the open-source ecosystem with the mannequin and coaching information available.
As a outcome, Stable Diffusion fits the extra technical crowd, who can construct on it, customise the mannequin and fine-tune settings to realize precisely what they need.
Midjourney provides a extra Apple expertise — easy with all the things understanding of the field. You inform the mannequin what you need, and also you’ll get it.
I’ll group these into two classes:
- Text-to-images. Leverage textual content prompts to create artwork, graphics and images.
- Text-to-videos. This is simply taking off and the outcomes aren’t tremendous simply but. Watch this area very fastidiously.
Text-to-image
Want an on the spot Raphael portray of Madonna and a toddler consuming pizza? You received it.
Generative artwork AI that absorb consumer prompts to create stunning and unusual pictures on demand has arguably seen probably the most competitors over the previous 12 months.
From OpenAI’s DALL-E to Midjourney to Stability AI’s Stable Diffusion — we’ve now received quite a lot of terrific AI webapps to create pictures of no matter you need utilizing easy textual content prompts.
How about this photo-realistic robotic for a sci-fi mission?

Or some meme-worthy enjoyable with celebrities? (More on that downsides of this later.)

How about some creative illustrations for an artbook mission?

Or maybe you’re after some inventory images in a jiffy?

Heck, what about producing a whole cowl in your journal?

Even the world of Non-Fungible Tokens (NFT) — the know-how used seize decentralised possession on the blockchain — has started leveraging AI to democratise NFT creation to the plenty.
MOOAR, a pioneering NFT launchpad constructed by the creators of the favored ‘transfer & earn’ app STEPN, lately launched an end-to-end service known as FairMint that allows customers to create a picture assortment with generative AI and launch them as NFTs straight onto the blockchain.
See right here and right here for examples of what customers have crafted on MOOAR.
FairMint frees up treasured time for creators to concentrate on issues like advertising and constructing utility for NFT holders, by making the artwork creation (abilities one could not possess) and blockchain deployment (sometimes requiring builders) all of the sudden as simple as pie.
Text-to-video
This is an rising use case and the outcomes are nonetheless unrefined in comparison with the unbelievable outcomes from text-to-image workflows.
This is to be anticipated as producing a rolling set of pictures that by no means existed is harder than simply creating one.
When GPT-4 was introduced in March 2023, we instantly noticed AI innovators and experimentalists try to leverage it alongside AI like Midjourney to create movies.
This concerned daily-chaining of various AI instruments with actual movie footage to provide one thing.
Barely a month later, the sport has already modified with NVIDIA’s new Video Latent Diffusion Model (VLDM). You can now immediately generate fairly-decent high quality movies straight from textual content prompts.
We’re far-off from Hollywood high quality outcomes, however as we’ve all come to see within the AI area, blink a couple of instances and all of the sudden you’re yesterday’s know-how.
I anticipate text-to-video efficiency to enhance shortly over the subsequent two years.
Perhaps at some point, we’ll not want to attend for animation and movie studios to create content material to feed our want for journey and escapism. Everyone might be geared up with the ability to create immersive visible narratives or whole digital worlds at a whim, probably skilled with metaverse applied sciences like AR and VR.
Prompt engineering
As hundreds of thousands internationally come to grips with learn how to greatest join thoughts with machine and generate the exact pictures they need, immediate engineering has emerged as a key ability to hone, refine and grasp.
Users are already stacking AI applied sciences collectively — like leveraging GPT-4 to assist write higher prompts in Midjourney V5.

Here’s a video from the proprietor of the favored SonyAlphaRumors web site explaining how he simply educated ChatGPT to assist him generate his type of images on Midjourney at a whim. All he did was present ChatGPT a listing of prompts created by different customers that generated his kind of images.
We’re seeing an growing variety of generative AI trailblazers uncover the secrets and techniques to higher prompts and documenting their discoveries and journey.
I anticipate the problem of writing efficient prompts will spur a whole guru business over the approaching years.
AI has democratised the flexibility to generate top-tier imagery to the plenty.
You not must be an expert artist, graphic designer, painter or photographer to create work of an expert calibre.
Log onto DALL-E or Stable Diffusion’s websites, or soar onto Midjourney’s Discord, string collectively a well-worded immediate and watch the magic occur in a minute.
As you may think about, that is unbelievable as each a technical functionality and in its far-reaching energy to disrupt all artistic industries.
Take for example, inventory images.
Shutterstock, a well-liked inventory images and pictures website that gives an enormous library of pictures, movies and music tracks for licensing, has a protracted historical past of collaborating with OpenAI.
In 2021, OpenAI leveraged the pictures and metadata Shutterstock had been promoting them to coach and create DALL-E.
DALL-E is now utilized by hundreds of individuals to generate pictures that’s in direct competitors with the work of Shutterstock’s contributors, a lot of whom could have had their content material used to coach the AI mannequin.

For inventory photographers who painstaking shoot their pictures in an expert studio and labour hours post-processing them to perfection, generative AI is posing a risk akin to an existential disaster.
More typically, AI artwork has opened a can of worms surrounding mental property, the creative course of, and the worth of artwork.
AI fashions are in the end educated on the work of actual artists, usually leading to its worth not being pretty shared with the hard-working artists who made it attainable.
Even with good intentions, it’s troublesome to share the spoils in a truthful approach, as AI content material leverage the IP of many artists,
This means AI-generated pictures can’t be copyrighted.
This might be why Shutterstock solely permits the sale of AI pictures produced by DALL-E, in order that they’ll observe the contributors.
Down the observe — as AI-generated work take cash, recognition and alternatives away from artists, will they proceed to provide artwork?
What turns into of the worth of artwork when AI flips the historically laborious creative course of — honed via years of devoted apply — the wrong way up?
Does clicking a couple of buttons and typing some prompts destroy the authenticity of what the idea of artwork means to people?
I can think about these vigorous debates will solely amplify as AI adoption and capabilities proceed to go up.
Another problem are deepfakes.
The issues generated from the benefit at which this know-how can be utilized to generate harmless impersonations or malicious fakery.
Anyone can now click on a couple of buttons to have some enjoyable at another person’s expense — with out considering via the results — or weaponise AI at scale to fan pretend information and fraud.
Barack Obama lately mirrored on his presidency as the primary set fully set within the digital age, making him probably the most recorded particular person (juicy information!) in human historical past.
“Today you may have me in nearly any setting on a video, and positively on a recording, say something. And until you’re Michelle, you’re fairly assured it’s me.
To protect democracies we’re going to have to spend so much extra time determining how are we educating our youngsters to kind out the variations between reality, opinion, falsehood, what appears to be like actual however isn’t. We’re going to have to coach our brains to catch as much as these new applied sciences.”
— Barack Obama, 2023

We lately noticed an explosion of deepfake artwork and memes that poked enjoyable on the indictment of Donald Trump previous to his imminent arrest. As it is a politically-sensitive problem with world-changing penalties, one can respect the gravity of problems from throwing deepfakes into the combo.
For some it may be enjoyable and video games however the potential of AI know-how to create discord, unfold pretend information and entrench an already polarised world — would require accountable administration.
We’re getting into a brand new period of moral points surrounding the flexibility of anybody to simply generate photo-realistic pictures, and shortly movies, of anybody else, not simply well-known politicians.
Ever the opportunist style — generative AI artwork has already infiltrated the pornography business, with cheeky startups leveraging the know-how to create clips with the faces of performers.
Text-to-image generative AI is turning into mature, with the newest platforms capable of generate photo-realistic imagery that will idiot most individuals.
Many artistic industries are being disrupted.
At the identical time, machine studying methods proceed to innovate at breakneck tempo. I anticipate text-to-video know-how to grow to be compelling inside three years.
We can even anticipated that as new flagship fashions are launched into the world, entrepreneurs and technical opportunists will shortly discover methods to increase their capabilities via…
- Customisation (e.g. coaching your individual Stable Diffusion mannequin);
- Extension (e.g. plugins);
- Stacking.
We’re already seeing the ‘stacking’ of a number of AI applied sciences collectively to kind an end-to-end service, equivalent to leveraging GPT-4 to generate wealthy textual content prompts for Midjourney V5.
I predict an explosion of AI startups — every excelling at a particular area of interest — creating specialised AI’s that technologists and customers will stack collectively in a modular net of AI micro-services to create new end-to-end AI merchandise.
Top entrepreneurs will scale their merchandise to grow to be unicorns.
This kind of know-how stacking mirrors the broader tech motion over the previous decade of migrating monolithic structure — the place a single platform does all the things — in direction of a mesh or net of nimble hyper-specialised micro-services.
Keep your eyes on this area because it is likely one of the most fun locations to be proper now.
Follow me on YouTube and Twitter.
Join Medium to take pleasure in limitless entry to the greatest analytics & information science articles on the web.
You can assist me and different high writers by becoming a member of right here.
- AI Revolution: Intro to Machine Learning — right here
- ChatGPT & GPT-4: How Deep Learning Revolutionised NLP — right here
- Generative AI Art: DALL-E, Midjourney, Stable Diffusion — right here
- Future of Work: Is Your Career Safe within the AI Age — right here
- Singularity: The Search for Superintelligence — right here
- Differential Equations versus Machine Learning — right here
- Math Modelling versus Machine Learning for COVID-19 — right here
- Predict House Prices with Regression — right here
- Predict Employee Churn with Classification — right here
- Popular Machine Learning Performance Metrics — right here
- Jupyter Notebooks versus Dataiku DSS — right here
- Power BI — From Data Modelling to Stunning Reports — right here