
Earlier Elements of this System Design Tutorial
- What’s System Design
- Evaluation of Monolithic and Distributed Methods
- Essential Key Ideas and Terminologies
- What’s Scalability and How you can obtain it
What’s a Database?
Once we retailer information, info, or interrelated information, in an organized method in a single place, it is named Database.
Databases are answerable for the storage and retrieval of information from a knowledge software. They’re a vital half as all the data is saved inside them so getting their design precept understanding is essential as with rising in large information a number of actions that contain our interplay with databases.

Full Reference to Databases in Designing Methods – Be taught System Design
Terminologies used within the Database:
- Information: Any statistics which is uncooked and unprocessed are referred as Information.
- Info: When information is processed, it is named Info. It’s because info provides an thought about what the info is about, easy methods to use it additional, and so forth.
- Database: Once we retailer information, info, or interrelated information, in an organized method in a single place, it is named Database.
- DBMS or Database Administration System: A system developed add, edit, and handle numerous databases in a group is named DBMS.
- Transactions: Any CRUD operation carried out on a database is known as a Transaction in Database. Each transaction in Database should comply with ACID property.
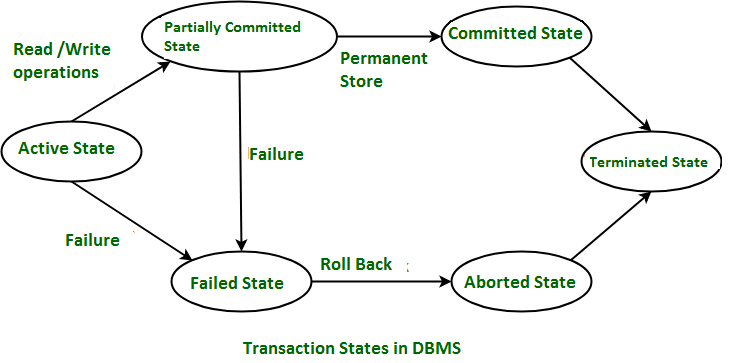
Transaction States in DBMS
Now we’re good to go along with discussing forms of databases first in-depth in order to grasp when, why and which database to go for designing functions.
They’re of three sorts as follows as listed and proven under media as follows:
- File-Based mostly DBMS (flat file type)
- Relational DBMS (tabular type)
- Non-relational DBMS (Non-tabular type)

Sorts of Databases
Databases Fundamentals In System Designing

Position of Database in System Design
Pre-requisite: CAP theorem which states that states that it’s not potential to ensure all three of the fascinating properties – consistency, availability, and partition tolerance on the identical time in a distributed system with information replication.
- Consistency: All nodes within the system must be responding with the newest information.
- Availability: Any node can ship a response.
- Partial Tolerance: Methods will carry on working even when communication is dropped between 2 nodes.
Now we’re good to go to debate the above database units as depicted under:
CP database
On this database when partitioning between any two nodes is going on a;; different no-consistent nodes are shut down therefore making them unavailable. This database delivers consistency and partition tolerance at expense of availability.

CP Database
AP database
Because the identify suggests consistency is getting misplaced on this database throughout partitioning all nodes on the incorrect finish of partition are made to ship older model of information. On this approach on this database, all nodes can be found however not constant.

AP Database
Observe: Now you have to be questioning about CA database which sounds deceptive as there isn’t any partitioning carried on. So all the time keep in mind partitioning is a property of a system which is telling CP or AP, which one to decide on .
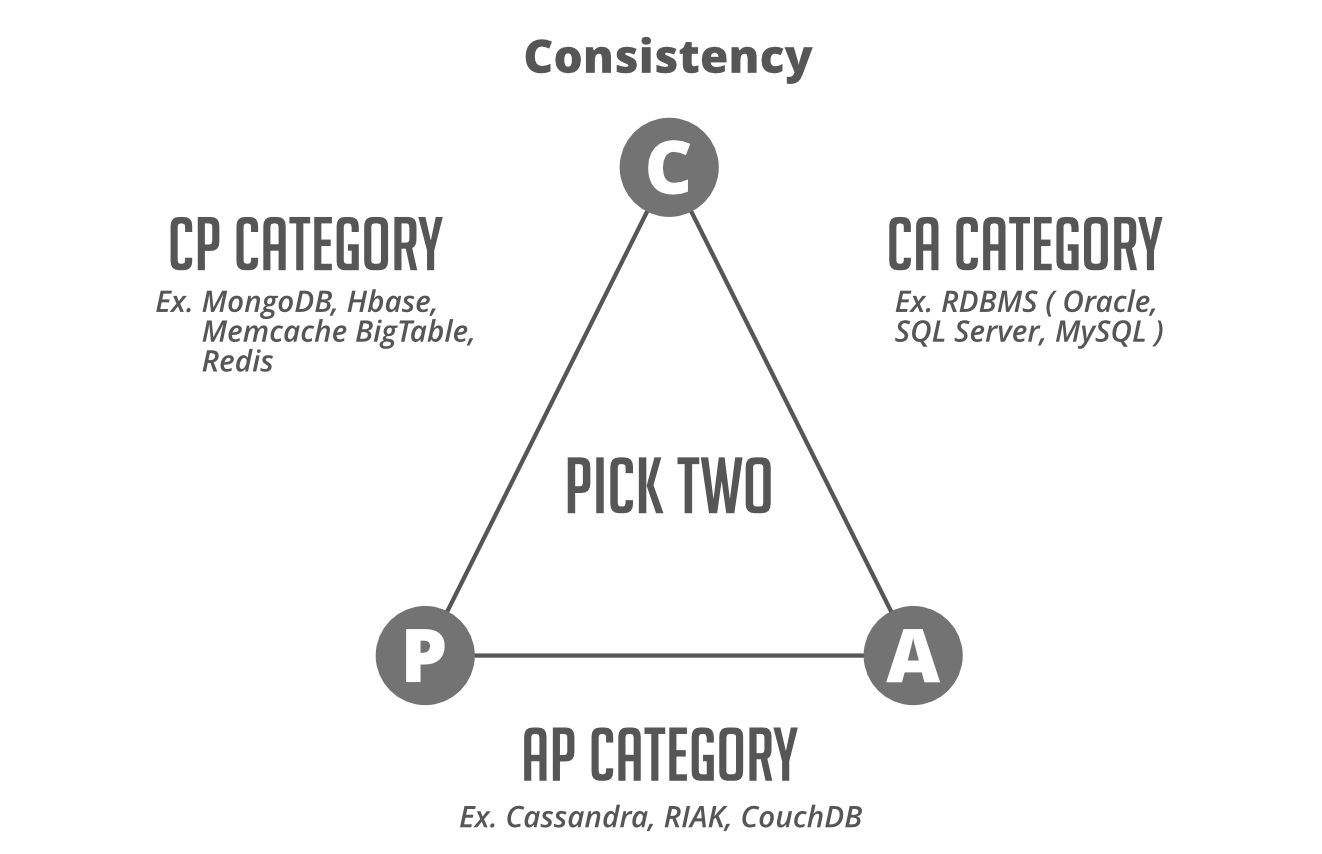
CA, AP and CP Databases
Fascinating reality: We see RDBMS databases at CA sides of triangle in above media which is just potential at single node setup as even in case of grasp(write)-slave(learn).
Observe: Typically when it is just referred to as CA to decrease diploma of extent for some causes the place it cant get well from community partitions than there split-bran state of affairs.(new grasp is elected for partitioning)
Blob Storage
Allow us to say we’re as much as designing a Uber system the place we’re as much as the reserving, renting cabs, and plenty of different companies.
Now right here the patron can be dropping textual content in order so as to simply talk or name or worst dropping a close-by photographs the place he/she desires to go. In order a driver might be there both by on-line name service or dropped picture landed for which we can be needing databases to retailer the pictures.
Wherever in a system we’re having photographs and movies they don’t seem to be immediately termed as databases and fairly are known as Blob storages as a result of we’re immediately placing them. So so as to work, no queries might be operated over them.
The under media depicts the system structure of the Uber app as follows so as to get showcasing information shops and to get an outline of database design:
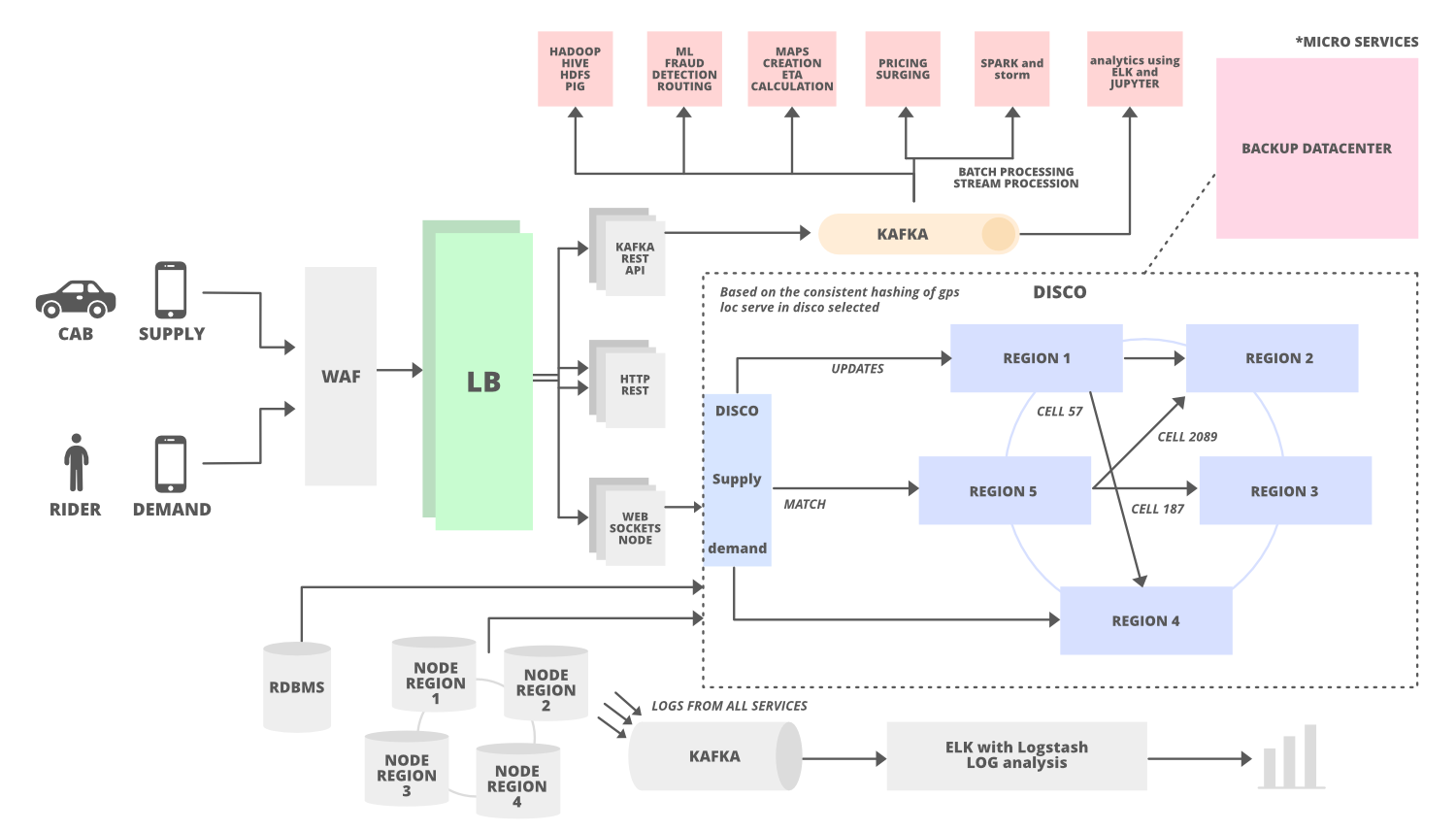
System Design Of the Uber App
Observe: Amazon S3 is among the high suppliers serving as information storage, also referred to as blob storage.
CDN(Content material Supply Community): Photos and movies which can be saved in datastores (Amazon S3)now have to be widespread throughout totally different servers throughout the globe as a result of there are humongous customers which can be querying for a similar as in comparison with databases widespread throughout in accordance to geographical places.
Blob = S3(Datastore) + CDN(Content material Supply Community)
Textual content Search Engine Capabilities: Now we would like customers to work together with the service then we have to present looking out through textual content of title and outline. Right here so as to assist looking out widespread search engine capabilities that are seen in lots of system architectures akin to Google Maps, Amazon Prime, and plenty of extra that we are able to simply consider. Now, this generally is supplied by Elastic search and Solr of which each are constructed on high of Apache Lucene.
Now assume of what’s going to occur if the consumer enters grammatically incorrect phrases whereas looking out how a textual content search engine can be working is as proven under as follows:
Fuzzy Search: It’s help performed alongside textual content search capabilities the place the consumer enters grammatically incorrect whereas typing corresponding if we don’t fetch any question end result will result in unhealthy consumer capabilities. Therefore we make our database sensible with this method by showcasing nothing.
Now allow us to contemplate a pattern system design be it Google, or Amazon the place we need to retailer the database for analytics on all of the transactions as per the system’s present or ongoing necessities then we do it a distinct approach. Right here we maintain a bigger chunk over all databases which is often generally known as information warehousing.
Information Warehousing: It’s launched the place all the info is dumped into the database in order to serve numerous queering capabilities to generate reviews. Information warehousing is usually not computed over on-line information however computed over offline information.
Instance: Hadoop
How you can choose the best database for the service?
It’s a very essential step in relation to databases in designing programs. To be able to get the best database for our information, we have to first look over 5 elements which can be as follows:
- Construction of Information
- Sample question
- Quantity of scalability
- Value
- Maturity of the database
Once we to make use of relational and non-relational database in system?
Once we are having structured information(tabular information) than utilizing relational database is perfect as a result of right here the info is in type of rows and columns and may simply be saved. Widespread examples: MySQL, oracle, postgres, SQL server.
But when we don’t want ACID properties than it’s upto us which one to decide on as per the necessities.
Selecting a database is depicted in a flowchart under as follows:

How you can Select Proper Database for our System
Observe: If we don’t want ACID properties , nor do wide selection question sorts and neither our information is ever growing than it immediately implies it’s a low scaled system with lesser variety of attributes over small dat set the place we are able to go for any of both datatypes.
Now allow us to evaluate through tabular format under as follows so as to select the most effective database as per our system design in order that we’re clear.
Challenges to databases whereas Scaling
We face an issue of elevated value for question operations it doesn’t matter what the kind of database. It’s as a result of the CPU is answerable for question operation whereas our information is saved in laborious disk(secondary reminiscence). Now CPU is computing 1,000,000 enter per second (MIPS) whereas our laborious disk is just doing <100 operations per second regardless of how briskly or not it’s. So they can not work together with one another immediately however must correspond to which we carry major reminiscence (RAM) into play which may function quicker through caching however it’s not optimized as perceived from the under media:
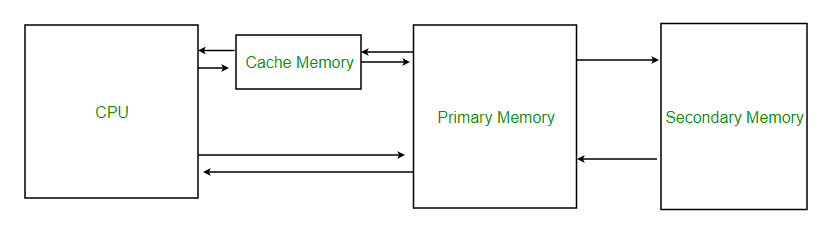
Relation between CPU and reminiscences In a Laptop
As seen above information is saved throughout sectors(blocks) in our secondary reminiscence and cannot be totally transferred to RAM else it will likely be misplaced utterly as studied within the working system we pay a value each time whereas dealing with out information.
How you can overcome challenges to Databases whereas Scaling
Now allow us to talk about under ideas that assist us in scaling our databases and overcoming these challenges which can be as follows:
- Indexing
- Information Partitioning
- Database Sharding
Allow us to first talk about indexing adopted by indexing and partitioning/ sharding.
What’s Indexing?
Indexing is a process launched for database operations and different queries (acquired by CPU) are optimized by lowering the period of time wanted to finish a question, indexing helps optimize queries and different database processes whereas fetching information in lesser time. The indexes are saved utilizing the B-tree information construction. Solely make the most of indexing if the info is very large and the applying requires a number of studying. Indexing might decelerate write operations if an software is write-intensive.
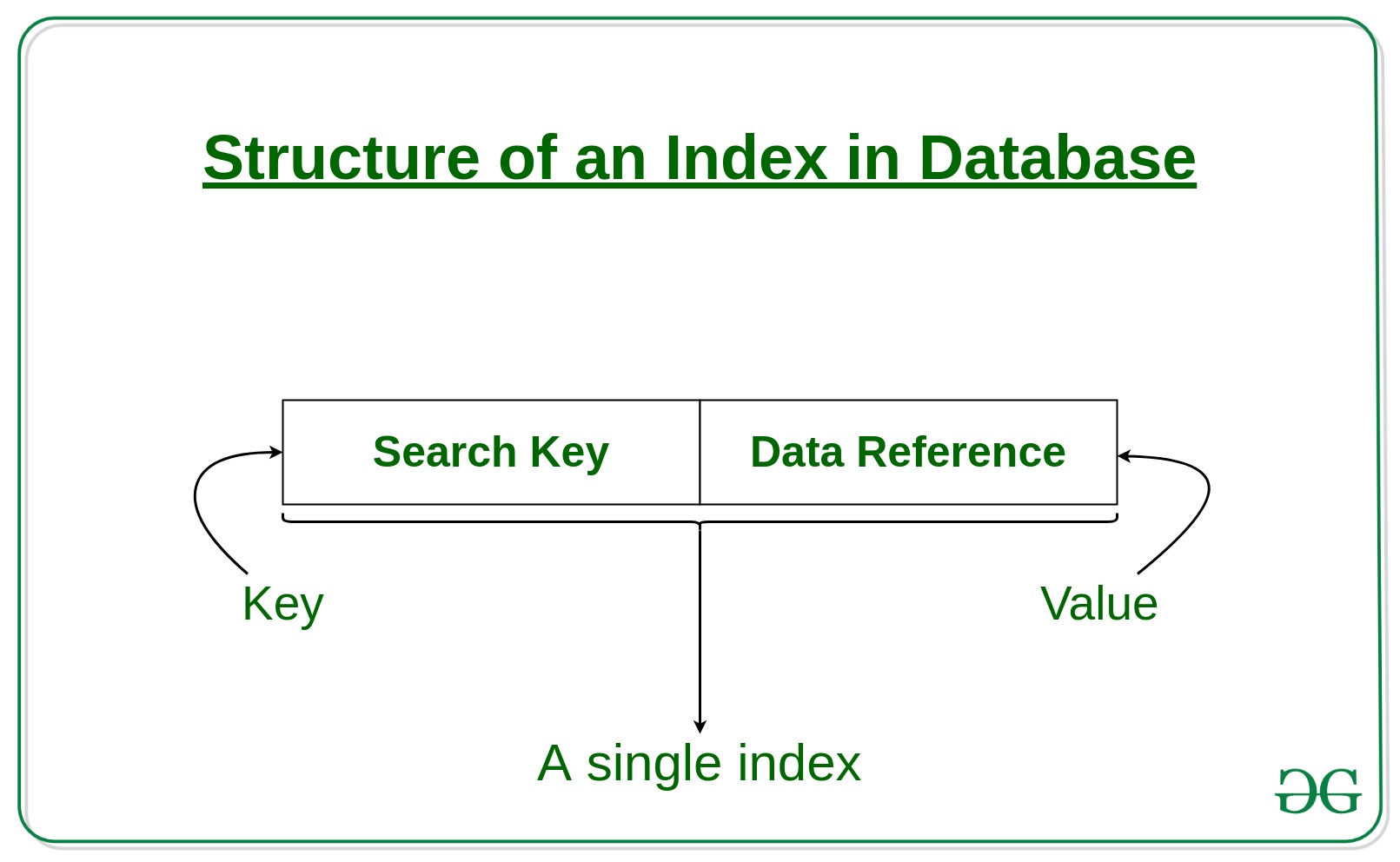
Construction of an Index in a Database
How indexing helps in lowering prices?
The information is fetched from secondary reminiscence in blocks as studied in OS. Observe right here information might be structured or non-structured. On the backend, the storage supervisor in OS does the job by placing all the info from logical drives into secondary reminiscence in a number of chunks of blocks generally known as sectors. Now, these blocks are fetched into primary reminiscence(RAM) the place we aren’t specializing in lowering the block dimension or altering it.
Right here in indexing when a single block is inserted in RAM directly and retrieval of information happens. If the reply to the specified question is fetched then it’s referred to as ‘cache-hit’ else it is named ‘cache=miss’.
Tip: There’s a value related to this cache hit-miss operation generally known as I/O value.
On this approach as a substitute of rolling the whole information into RAM which takes an unlimited period of time as a value in designing the mannequin, with indexing the identical information might be fetched simply possible what we’ve got had in books.
Illustration:
SELECT * from GFGEmployees the place Title = Mayank Solanki;
Now if we don’t apply to index we’ve got to place the entire file from the group listing to RAM for only a fundamental question whereas with assist of indexing regardless of how large the group scales up cache hit-and-miss operations drastically scale back the price not just for this question however even to complicated ones as there can be solely hit and miss operation. If fetched, hit else cache-miss.
Instance:

Indexing in a Desk In a Database
Observe: Indexing and hashing in a database are crucial from an interview perspective as it’s been requested in lots of system design interview.
Benefits of Indexing
Indexing has a number of advantages, together with
- Sooner SELECT queries.
- Makes a row distinctive or helps to eradicate duplicates from a row.
- We will search towards enormous string values for full-text indexes, akin to finding the string for a substring.
Disadvantages of Indexing
- The replace course of is sped up if the the place circumstances consult with an listed area, however the Insert, Replace, and Deletes question is slowed down as a result of the index should even be up to date whereas updating.
- Additional room is required for the indexing components.
Now after having an understanding of the idea of indexing allow us to adhere ahead to the idea of partitioning.
What’s Information partitioning?
It’s a database process of partitioning that entails breaking apart a really massive desk into quite a few smaller sections. Queries that entry solely a tiny portion of the info can run quicker since there may be fewer information to scan when enormous tables are divided into smaller particular person tables. When the quantity of information is massive and a single system can not deal with it, partitioning is used.
Now allow us to talk about totally different strategies of reaching partitioning that’s as follows:
Partitioning Strategies
There are 3 forms of partitioning which can be listed under and later mentioned as follows:
- Horizontal Partitioning
- Vertical Partitioning
- Listing based mostly Partitioning
Allow us to talk about them intimately for higher understanding as follows:
1. Horizontal Partitioning: With out the necessity to make separate tables for every portion, horizontal partitioning divides large tables into smaller, extra manageable items. A partitioned desk’s information is bodily saved in row teams generally known as partitions. It’s potential to entry and save every partition independently. In horizontal partitioning, every shard has the identical schema because the guardian database.
Software: Zipcode
Observe: Additionally it is generally known as shading or typically referred as range-based partitioning.
2. Vertical Partitioning: Tables with fewer columns are created utilizing the vertical partitioning method, and the remaining columns are saved in new tables. Information is offered in a vertical format.
The principle function of vertical desk partitioning is to extend SQL Server pace, notably when a question must fetch all columns from a database with a number of textual content or BLOB columns.
Software: Massive Studies(be it of any area)
3. Listing-based Partitioning: A search operate that’s conscious of the partitioning construction and decouples it from the database entry code. It allows modifying the partitioning scheme or including new database servers with out impacting the applying. It ends in a horizontally scalable software that’s loosely linked. Since key-based partitioning requires the usage of a hash operate that can not be usually up to date.
- Listing-based partitioning is extra adaptable than key-based or range-based partitioning.
- Vary-based partitioning establishes vary values that can not be modified.
Nevertheless, since directory-based partitioning is a extra dynamic methodology and is subsequently extra versatile, we are able to use any method to assign information to the shards.
Now geeks you have to be questioning what’s the creteria behind above mentioned strategies of partioning. So allow us to do talk about them now to get grasp understanding over idea of partioning that’s as follows:
Partition Standards:
- Key or Hash-based Robin Partitioning: To find out the partition quantity, we apply the hash operate to the entry’s key attribute.
- Record Robin Partitioning: The column that corresponds to one of many units of discrete values is used to decide on which partition to make use of. A set of acceptable values is assigned to the precise partition.
- Spherical Robin Partitioning: The ith tuple is assigned to partition quantity ipercentn if there are n partitions. This suggests that (ipercentn) nodes would obtain the ith information. Sequential assignments are made to the info. The distribution of information is assured by this partitioning criterion.
- Constant hashing: This type of division is novel. The hash-based partitioning had the disadvantage of requiring a change within the hash operate when including new servers. A server outage and information redistribution would end result from altering the hash operate.
Benefits of Partitioning:
- Efficiency Optimization
- Availability
- Load Balancing
- Scalability
- Extra manageable
Disadvantages of Partitioning:
- The complexity of the software program have to be maintained, together with the logic for routing inquiries and aggregating compute outcomes.
- Further {hardware} administration: extra DevOps work.
- Further overhead when redundancy.
What’s Sharding?
Sharding is an important idea that helps the system to maintain information in numerous assets based on the sharding course of. The phrase “Shard” means “a small half of a complete“. Sharding means dividing a bigger half into smaller components. In DBMS, Sharding is a sort of database partitioning during which a big Database is split or partitioned into smaller information and totally different nodes. These shards aren’t solely smaller, but additionally quicker and therefore simply manageable.
Illustration: Now allow us to contemplate two eventualities the place there isn’t any sharding and in different, we can be having easy sharding through medias to grasp it higher as follows:

No sharding
.png)
Easy Sharding
Want for Sharding
Think about a really massive database whose sharding has not been accomplished. For instance, let’s take a Database of a faculty during which all the scholar data (current and previous) in the entire faculty are maintained in a single database. So, it might comprise a really massive variety of information, say 100, 000 data. Now when we have to discover a scholar from this Database, every time round 100, 000 transactions must be accomplished to seek out the scholar, which may be very very expensive.
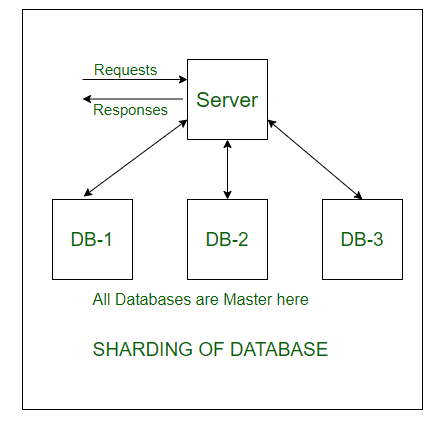
Sharding Of A Database
Now contemplate the identical faculty college students’ data, divided into smaller information shards based mostly on years. Now every information shard may have round 1000-5000 college students’ data solely. So not solely the database turned way more manageable, but additionally the transaction value every time additionally reduces by an enormous issue, which is achieved by Sharding. Therefore for this reason Sharding is required.
Options of sharding:
- Sharding makes the Database smaller
- Sharding makes the Database quicker
- Sharding makes the Database way more simply manageable
- Sharding generally is a complicated operation typically
- Sharding reduces the transaction value of the Database
- Every shard reads and writes its personal information.
- Many NoSQL databases supply auto-sharding.
- Failure of 1 shard doesn’t have an effect on the info processing of different shards.